
Чтобы извлечь данные лишь с нескольких десятков (пусть даже сотни-другой страниц), вам вполне хватит Google Таблиц. Давайте разберемся, какие для этого есть функции, на каких языках нужно писать запросы и как расширить функционал с помощью скриптов.
Примеры и шаблоны будут лежать в этой таблице. Чтобы что-то редактировать, заберите документ себе через «Файл» → «Создать копию». При запуске скриптов Google будет ворчать — нужно продолжать несмотря ни на что ;-)
Важно! Для больших объемов данных этот способ не сработает: чтобы спарсить аккаунты соцсетей, сотни тысяч страниц какого-нибудь Авито или просто крупного сайта, потребуется платный софт или отличное знание Python.
Специализированные функции Google Таблиц для парсинга данных: IMPORTHTML, IMPORTFEED, IMPORTDATA и IMPORTXML
IMPORTHTML
Функция импортирует данные со страницы, если они находятся в таблице или списке. Принимает три аргумента:
- Ссылку (с указанием протокола, например, https).
- Запрос (только два варианта — «table» для таблиц и «list» для списков).
- Индекс (порядковый номер элемента).
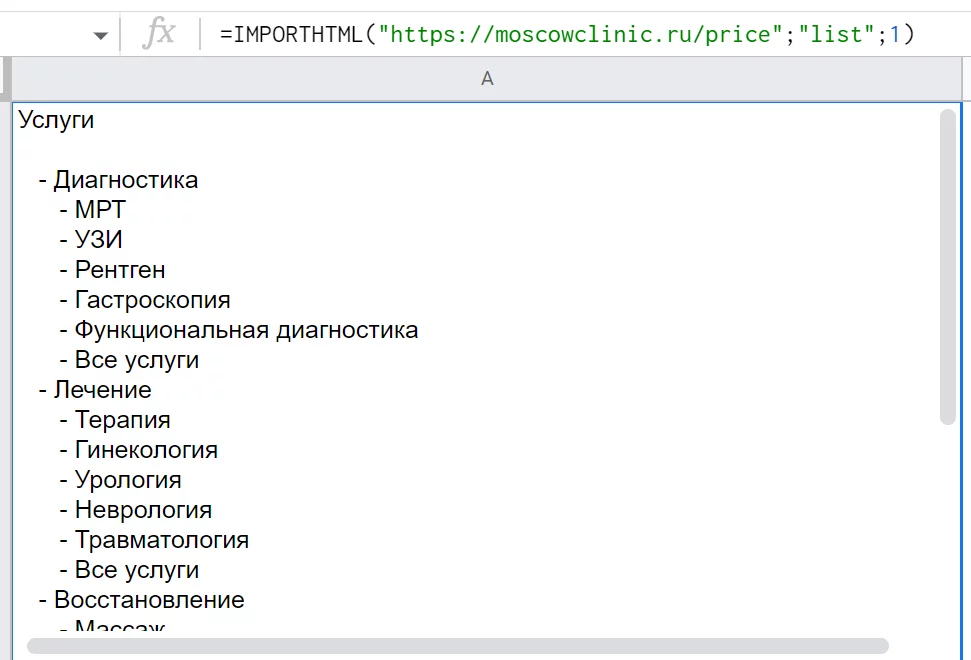
Например: =IMPORTHTML («https://moscowclinic.ru/price/diagnostika/mrt/golova»;"table";1)
.png)
В данном случае прайс-лист на странице оформлен с помощью тега «table» — это видно, если посмотреть исходный код. Поэтому все подтягивается нормально.
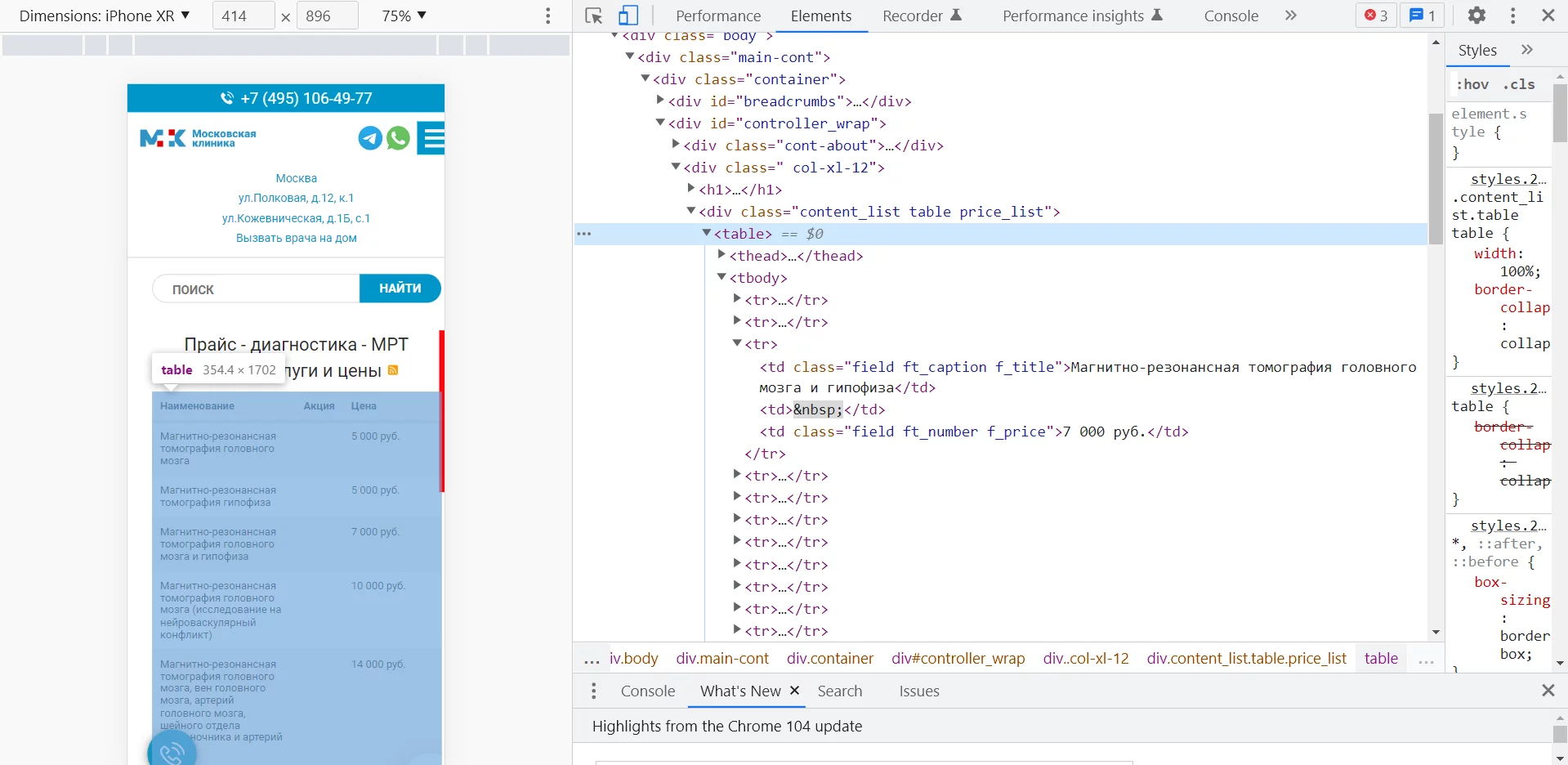
А вот на соседней странице этого же сайта, где общий прайс-лист, для верстки использовали тег «div». И IMPORTHTML с параметром «table» уже не справляется. А перебор «list» с разным индексом только вытягивает разные элементы меню.
Как видно из этого примера, на практике нужные данные не всегда лежат в таблицах и списках → IMPORTHTML редко позволяет решить задачу. Идем дальше.
IMPORTFEED
Импортирует ленту RSS или Atom в гугл-таблицу. Эта функция более интересная, особенно для тех, кто занимается контент-маркетингом.
Параметры:
- Ссылка на фид.
- Запрос — указываем, какие именно данные нужно загрузить.
(Например, можно прописать «items url» для выгрузки списка ссылок на новые статьи. Или «items title» — для их заголовков, соответственно. А с помощью запроса «items created» можно выгрузить даты публикаций.)
- Заголовки — тут нужно указать TRUE (1) или FALSE (0). Если TRUE, то первой строкой будут заголовки столбцов фида: например, «URL» или «Title».
- Число объектов — указываем цифру. К примеру, можно вывести в таблицу только последние десять материалов из фида.
Пример: =IMPORTFEED («https://www.unisender.com/ru/blog/feed/»;"items url";1;10)
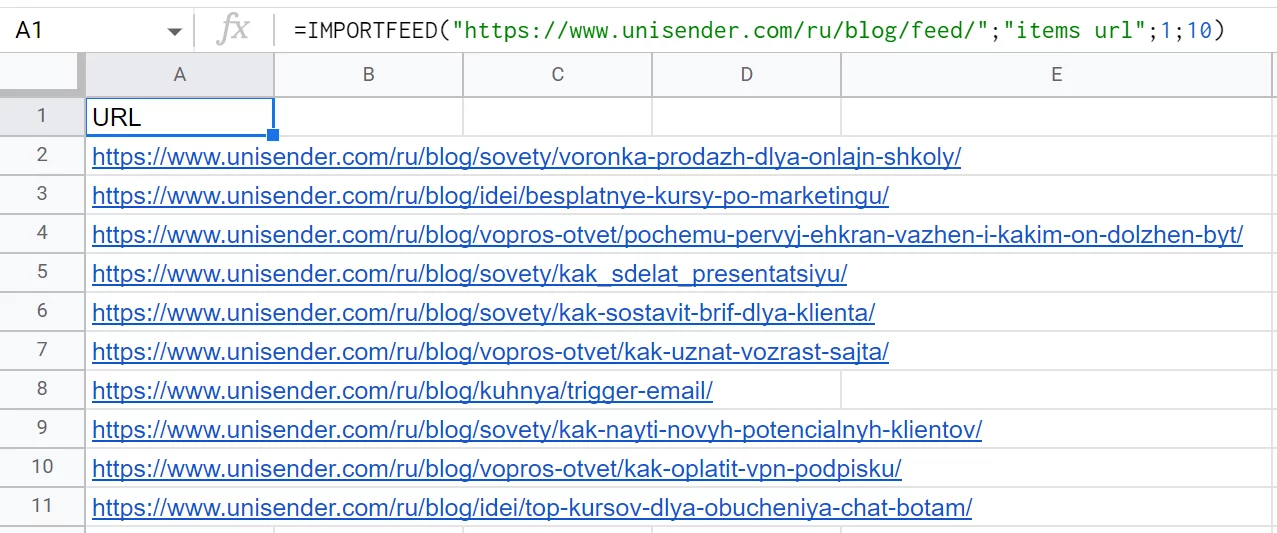
Такая формула выводит ссылки на последние 10 статей, которые опубликовали в блоге Unisender. (В соседнем столбце с этих URL уже можно спарсить количество просмотров, чтобы оценить популярность — это рассмотрим позже, в разделе про IMPORTXML и xPath.)
IMPORTDATA
Импортирует данные в форматах CSV и TSV (с XLS или XLSX, к сожалению, не работает). Синтаксис простой, аргумент один — ссылка на файл.
Пример: =IMPORTDATA («https://rssexport.rbc.ru/publisher/main_main/motion-design.csv»)
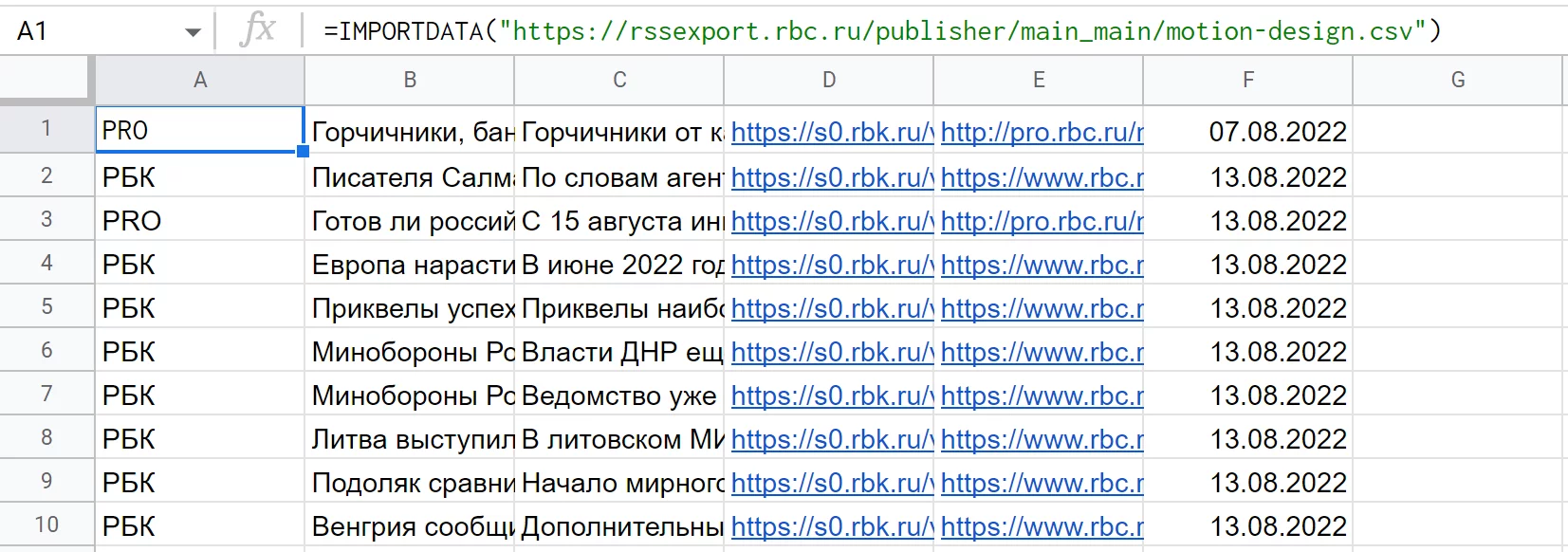
В данном случае, видимо, какой-то фид РБК в формате CSV — так он выглядит при загрузке в таблицу.
Эта функция тоже на практике используется гораздо реже, чем IMPORTXML, которую разберем следующей.
IMPORTXML
Эта функция может импортировать в самых разных форматах (XML, HTML, CSV, TSV, RSS, ATOM XML). Кроме того, язык запросов xPath очень функциональный и гибкий. Он позволяет точно найти нужный элемент на странице и извлечь из него все необходимые данные (процесс чем-то напоминает ориентирование в файлах и папках на компьютере). Поэтому разберем ее подробней.
Гид по мощной IMPORTXML и языку xPath
Сама функция IMPORTXML работает со следующими параметрами:
- Полный адрес веб-страницы — с указанием протокола, как и в других функциях Google Таблиц, которые начинаются с IMPORT. (Плюс, как и в других функциях, можно брать значения из ячеек.)
- Сам запрос xPath — передается текстовой строкой.
- Специальный код для указания языка и региона, но это необязательный параметр, по умолчанию Sheets возьмут настройки самого документа.
Простой пример: =IMPORTXML («https://vc.ru»;"//title")
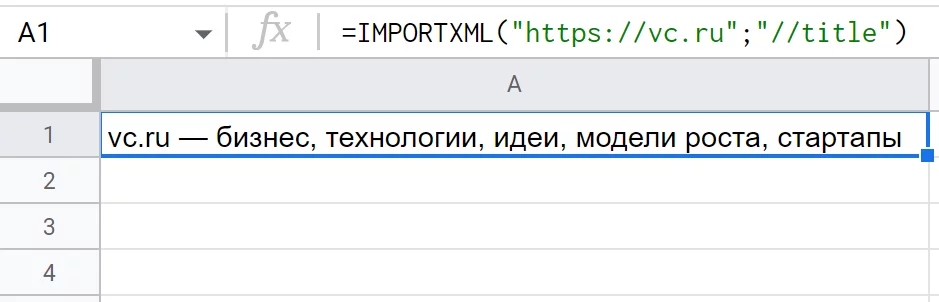
Функция находит тег «title», добывает SEO-заголовок страницы. Другой пример с парсингом метатегов: =IMPORTXML («https://rb.ru/»;"//meta[@name='description']/@content")
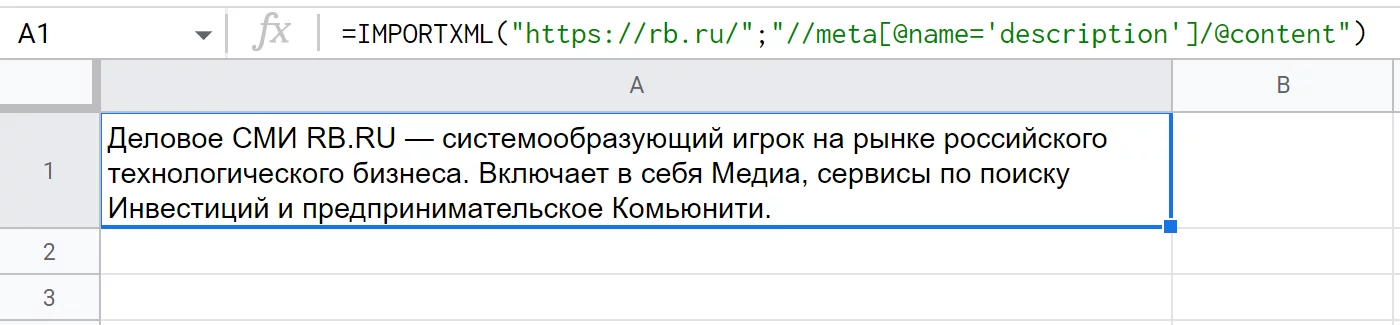
Почему запрос стал сложнее? Если открыть исходный код, то хорошо видно — в отличие от «title», тегов «meta» много. Поэтому мы указываем дополнительное условие — чтобы аргумент «name» был равен «description». А после мы еще прописываем, что данные нужно взять из другого атрибута этого же тега — «content». А с «title» проще, потому что там нужные данные лежат прямо внутри этого тега.

Теперь вернемся к идее из раздела про IMPORTFEED — дополнить список последних статей данными по просмотрам. Чтобы правильно составить запрос xPath, нужно открыть исходный код одной из них. Видно, что цифры лежат в теге «div» с атрибутом «class», равным «views».
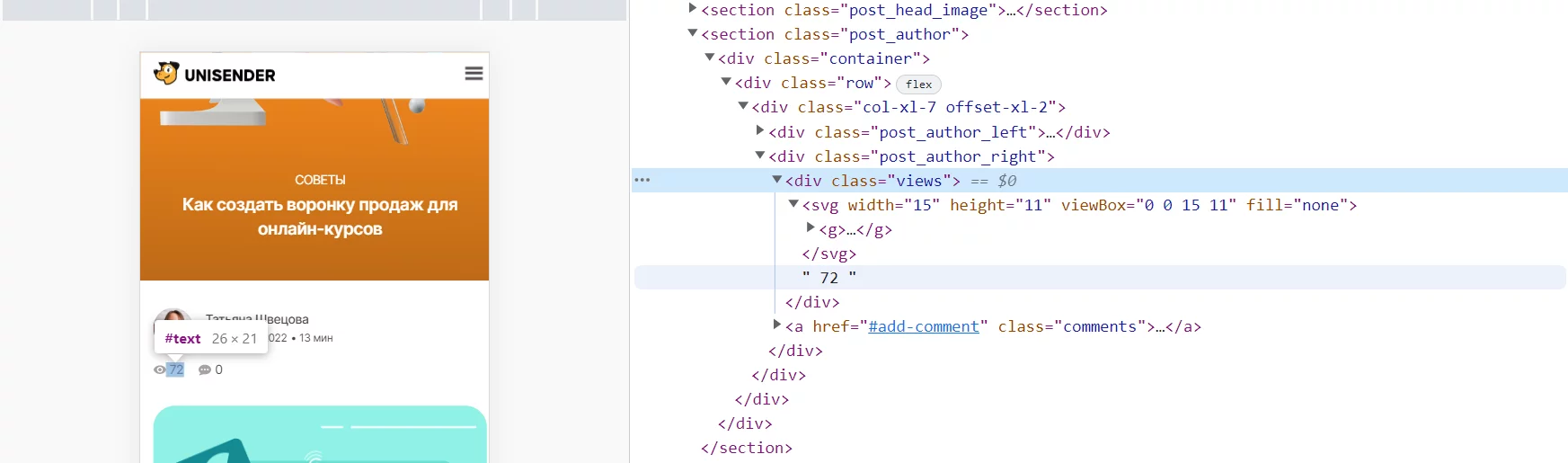
Кстати, прямо в инструментах разработчика Chrome можно нажать «Ctrl + F» и проверить, работает соответствующий запрос xPath или нет. Вводим //div[@class='views'] — найден новый элемент и в единственном числе. То, что нужно.
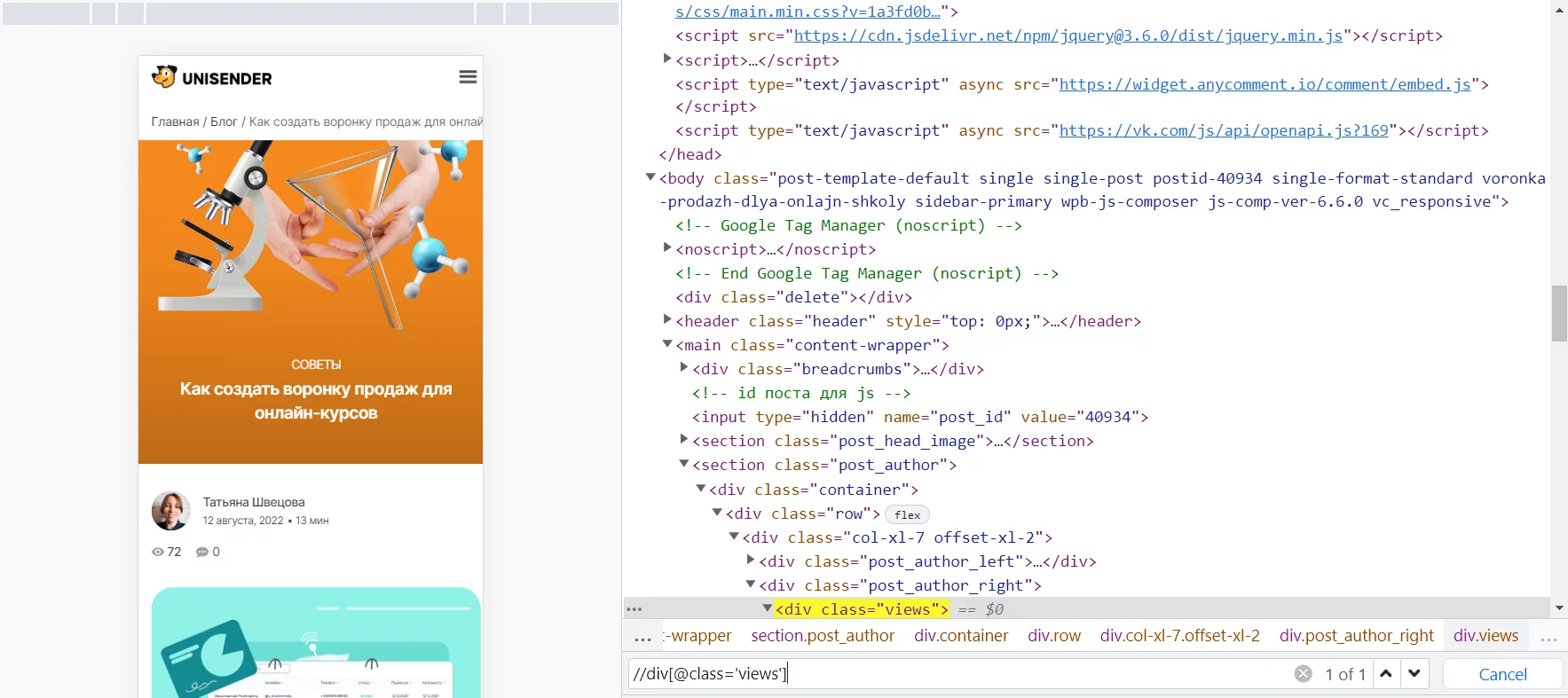
Вставляем этот запрос в формулу Google Spreadsheets — работает, но не очень красиво. Данные попадают на соседний столбец, все из-за лишних символов в теге.
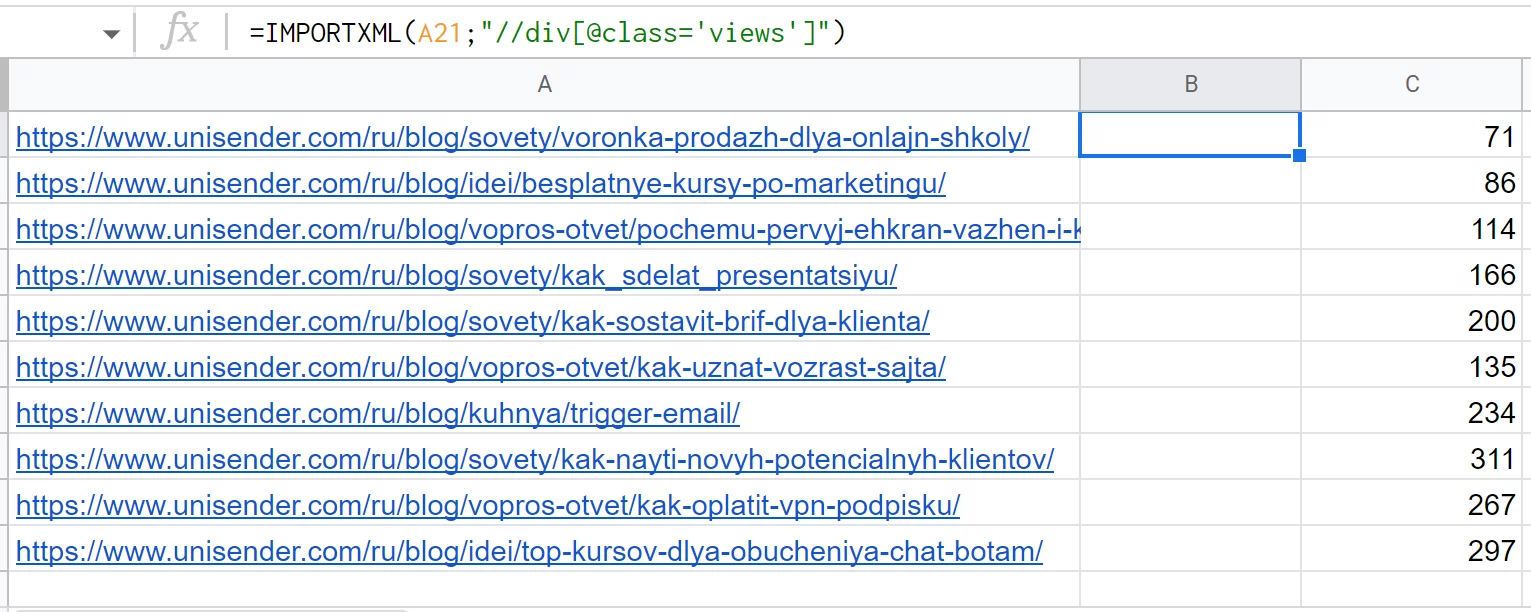
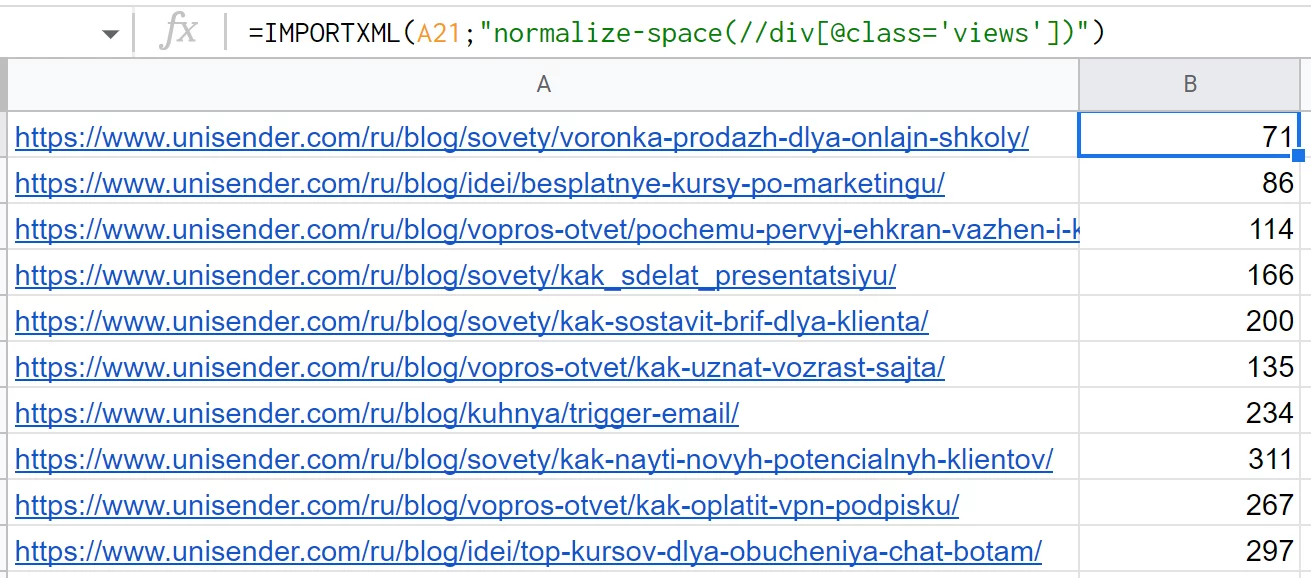
Для таких случаев в xPath есть дополнительные функции. Если переписать запрос так — normalize-space (//div[@class='views']) — все работает и выглядит нормально.

Google Таблицы не позволяют пользоваться функциями вроде IMPORTXML бесконечно — есть определенные квоты.
Поэтому все начинает тормозить, если подобных формул будет много. Таким образом можно потерять и уже собранные данные, так как по умолчанию все формулы пересчитываются при любом изменении в таблице.
Как расширить возможности парсинга с помощью пользовательских функций Google Таблиц (Google Apps Script)
Есть два надежных способа расширить лимиты с помощью Google Apps Script.
GAS — это скриптовый язык на основе JavaScript, который позволяет создавать дополнительные функции, автоматизировать работу с продуктами Google: Таблицами, Документами, Презентациями, Формами.
Best practice IMPORTXML
Эксперты телеграм-канала «Google Таблицы» пошерили таблицу, которая позволяет увеличить стандартные возможности IMPORTXML.
Скрипт (запускается при клике на инонку ракеты) получает данные и сразу заменяет формулы на значения, что позволяет уменьшить количество запросов → стандартных квот хватит дольше.
К тому же прошлые данные сохраняются, так как функция просто создает новые строки с новыми результатами. Отличить старые данные от новых позволяют дата и время.
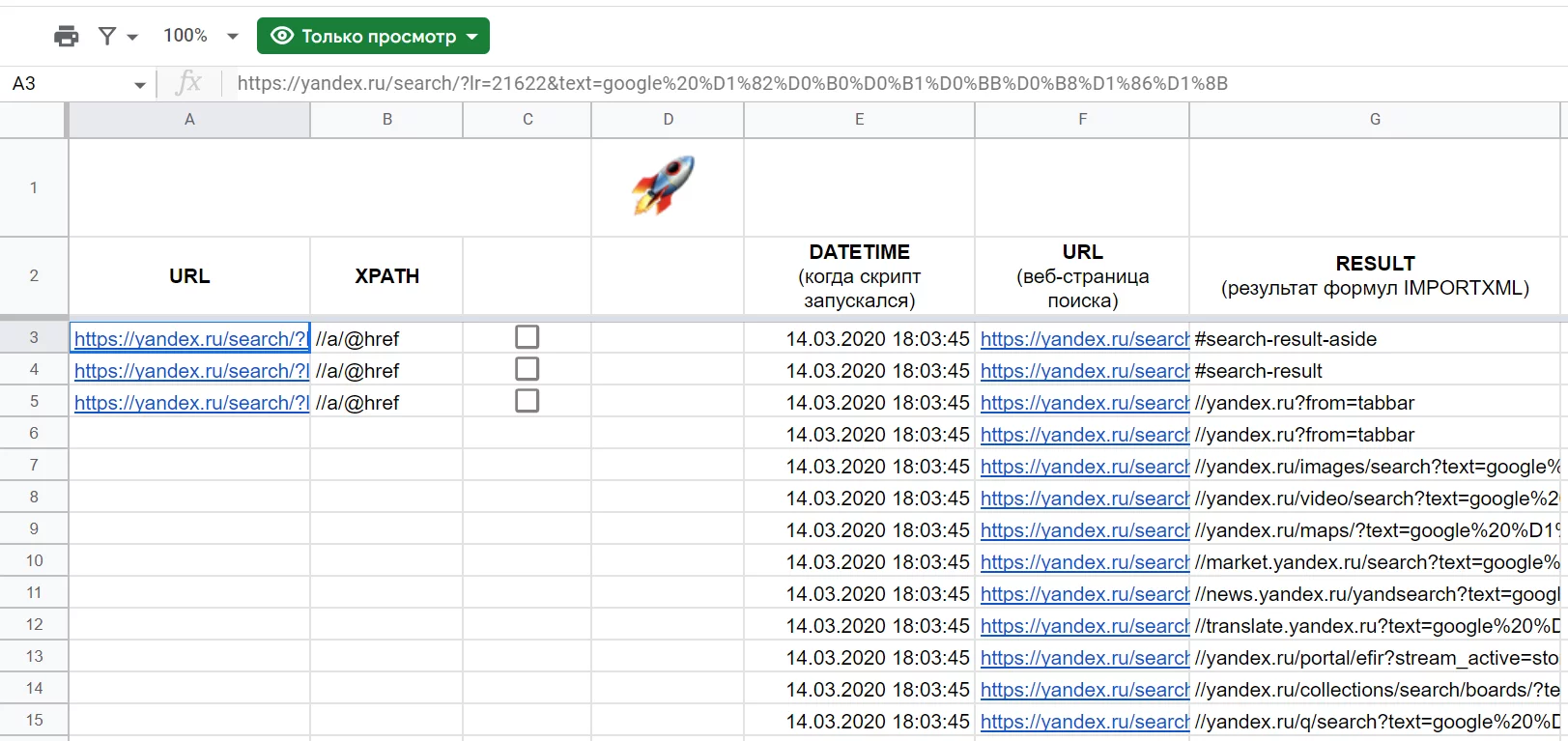
Ссылка на таблицу: https://docs.google.com/spreadsheets/d/17wuPFKmDM1wdDgkAJ9mOntkXyQ2KLch-x3KxZ1XvGEQ/edit
Чтобы что-то редактировать, нужно забрать документ себе через «Файл» → «Создать копию». При запуске скриптов Google будет ворчать, что скрипт непроверенный — нужно не поддаваться и продолжать ;-)
Если не хочется связываться с Google Apps Script, можно действовать похожим образом и вручную. То есть протягивать формулу → получать результаты → сразу заменять формулы на значения. Функции не будут собирать много данных — квоты закончатся нескоро. Но ручной способ, конечно, требует больше времени и сил.
IMPORTREGEX (IMPORTXML «на стероидах» и с регулярными выражениями)
Один из пользователей Stack Exchange опубликовал замечательный скрипт, который использует метод UrlFetchApp — у него тоже есть лимиты, но они значительно превышают квоты обычных функций Google Таблиц вроде IMPORTXML.
Еще ключевое отличие в том, что эта пользовательская функция работает с регулярными выражениями, а не xPath. Иногда нужные данные проще спарсить через xPath, иногда через регулярки.
Пользовательская IMPORTREGEX принимает два аргумента: ссылку на страницу и само регулярное выражение в формате текстовой строки. Например: =IMPORTREGEX (A1;"<\/g> <\/svg>\D*(\d*)")
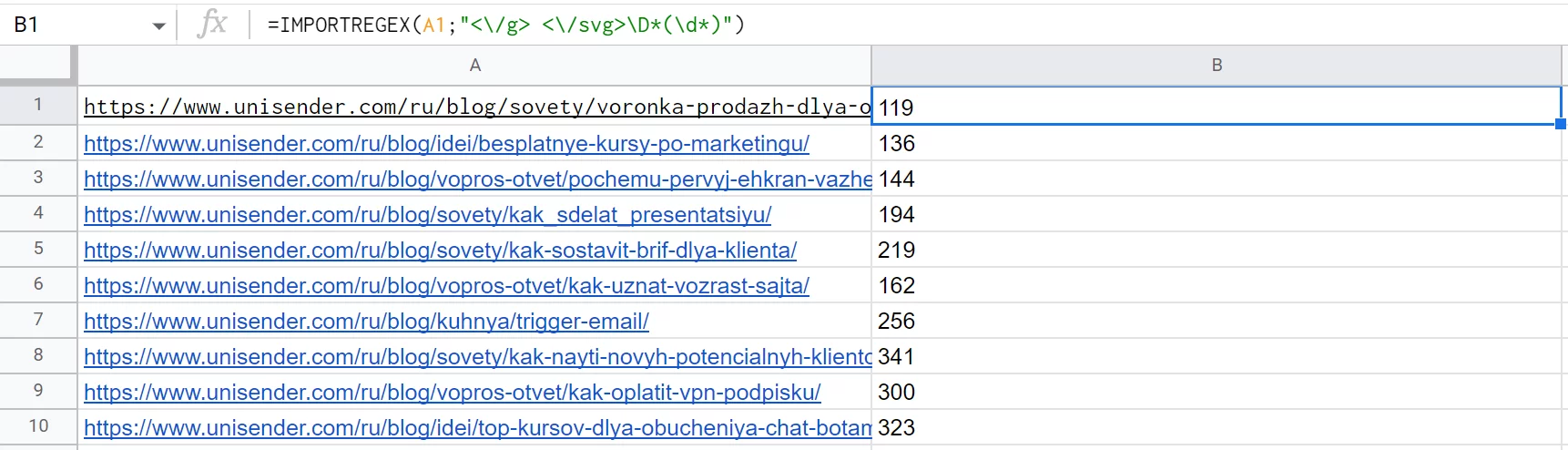
Решаем ту же задачу, что и в разделе про IMPORTXML и xPath — получаем количество просмотров у статьи Unisender. Только запрос теперь выглядит совсем по-другому. Но принцип работы похожий: нужно покопаться в исходном коде, найти уникальный элемент и правильно спарсить эти данные.
Разберем подробнее этот же пример. Как мы помним, искомые цифры находятся внутри тега «div» с классом «views». Но по коду видно, что их разделяет еще много тегов и данных. С xPath нас это не волновало, а регулярные выражения работают иначе — по сути это шаблоны для поиска текста. И чтобы запрос не занял несколько страниц, нужно брать фрагмент кода поближе.
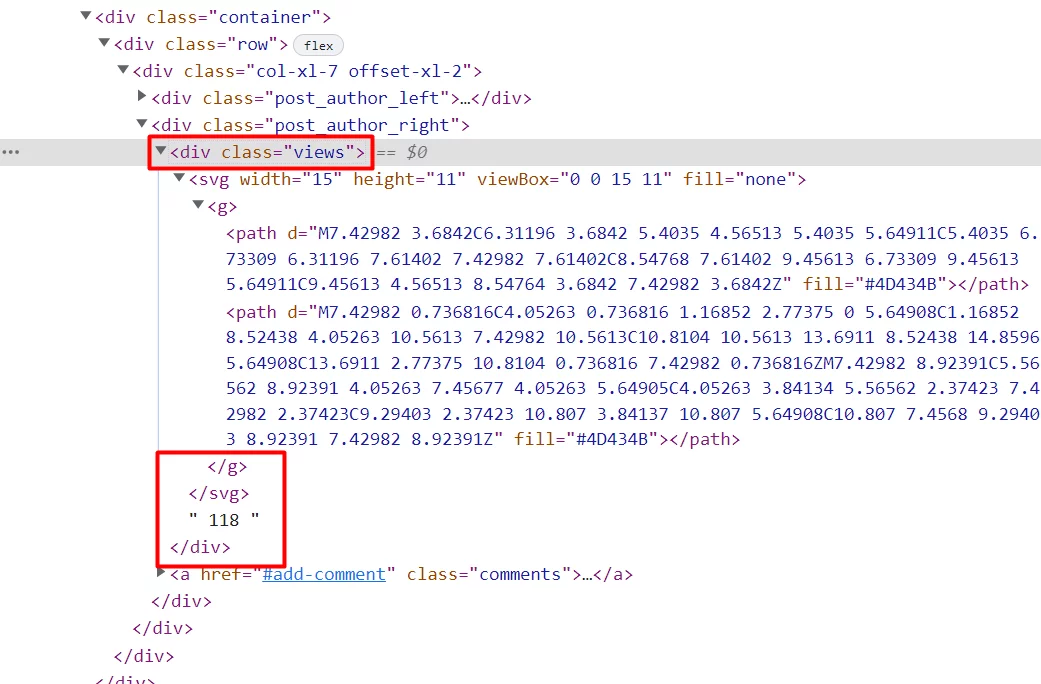
Непосредственно рядом с нужными данными есть закрывающие теги «g» и «svg». Если поискать в исходном коде этот кусок </g> </svg>, получится только одно совпадение. Фрагмент уникальный — значит, подходит.
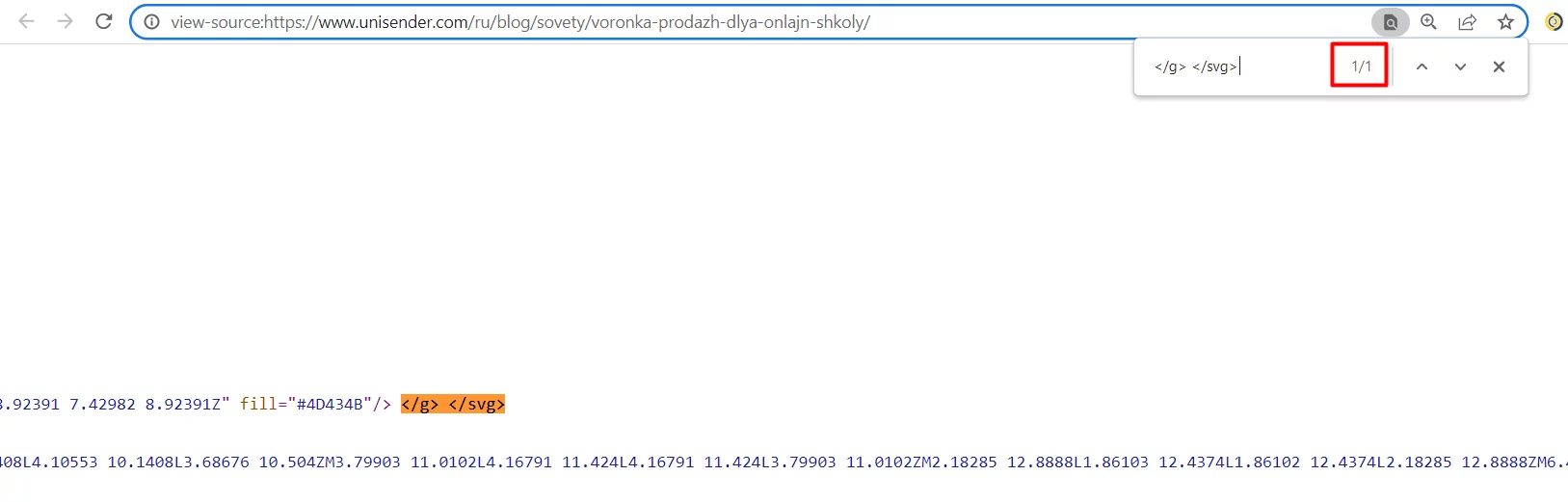
Слеш — один из служебных символов языка. Чтобы находить такой символ в тексте, нужно использовать экранирование с помощью обратного слеша. Поэтому все начинается с конструкции <\/g> <\/svg>.
В коде видно, что цифры идут не сразу после закрывающего тега «svg», а там еще пробелы и перенос строки. То есть нам нужно проигнорировать вот эти пробелы и энтеры, а взять только цифры, которые идут после. Это можно решить благодаря так называемым предопределенным классам. /D ищет любые символы, которые не являются цифрами, а /d — только цифры соответственно. Дальше с помощью * показываем, что такой символ будет не один, а скобками — группу символов, которую как раз нужно будет спарсить. Так и получается <\/g> <\/svg>\D*(\d*)
Чтобы IMPORTREGEX действовала в вашей таблице, можно скопировать наш шаблон и разрешить запускать скрипты. Или:
1. Открыть свой файл, затем выбрать в главном меню «Расширения → Apps Script».
2. Вставить следующий код:
function importRegex (url, regexInput) {
var output = '';
var fetchedUrl = UrlFetchApp. fetch (url, {muteHttpExceptions: true});
if (fetchedUrl) {
var html = fetchedUrl. getContentText ();
if (html.length && regexInput. length) {
output = html. match (new RegExp (regexInput, 'i'))[1];
}
}
// Grace period to not overload
Utilities.sleep (1000);
return unescapeHTML (output);
}
var htmlEntities = {
nbsp: ' ',
cent: '¢',
pound: '£',
yen: '¥',
euro: '€',
copy: '(c)',
reg: '®',
lt: '<',
gt: '>',
mdash: '-',
ndash: '-',
quot: '"',
amp: '&',
apos: '\''
};
function unescapeHTML (str) {
return str. replace (/\&([^;]+);/g, function (entity, entityCode) {
var match;
if (entityCode in htmlEntities) {
return htmlEntities[entityCode];
} else if (match = entityCode. match (/^#x ([\da-fA-F]+)$/)) {
return String. fromCharCode (parseInt (match[1], 16));
} else if (match = entityCode. match (/^#(\d+)$/)) {
return String. fromCharCode (~~match[1]);
} else {
return entity;
}
});
};
3. Нажать на иконку «Сохранить проект».
4. Теперь в таблицах можно вызывать IMPORTREGEX как и любые другие стандартные функции.
Якоря:
^EdTech — поиск строки, которая начинается с «EdTech».
продаж.$ — ищем текстовый фрагмент, который заканчивается на «продаж.».
Квантификаторы:
o+ — если находится один или более символов «o».
10* — соответствует тексту, где после 1 идет 0 или более символов «0».
0{6,} — ищем фрагмент, где подряд идут 6 нулей или больше.
Символьные классы:
\d — любая цифра.
\D — любой символ, который не является цифрой.
\s — любой пробел, табуляция или прерывание строки.
[А-Яа-я] — любой символ кириллического алфавита без учета регистра.
Операторы:
Телеграм[у|е] — находит строки «Телеграму» и «Телеграме».
\$\d+ — берем только знаки доллара и цифры после них (знак доллара нужно экранировать обратным слешем, чтобы найти в тексте, потому что это один из операторов).
<\/g> <\/svg>\D*(\d*) — ищем совпадения с тегами и символами, кроме цифр, но берем только цифры (обозначаем нужную группу скобками).
Для углубленного изучения языка:
Бесплатный интерактивный курс на Scrimba
regex101.com — мощный онлайн-сервис для обучения, тренировки и отладки чужих выражений.
Читайте также: 10 самых важных метрик продукта
на журнал




