

Автор статьи, интернет-маркетолог
25 января 2023 года произошла утечка более 44 ГБ исходного кода продуктов компании «Яндекс». Среди прочего, в архиве содержались файлы с алгоритмами и факторами ранжирования поискового сервиса.
Событие наделало много шума в русскоязычном и мировом сообществе SEO-оптимизаторов. В основном, в русских профессиональных блогах писали о файле factors_gen.in, который содержал в себе 1922 фактора ранжирования Яндекс. При детальном изучении архива можно было найти еще больше файлов с факторами ранжирования.
Удивительно, что глубокой аналитикой занялся не русский, а зарубежный SEO-специалист — Майкл Кинг, который написал статью с анализом документов «Яндекса» на Search Engine Land. При помощи соавторов, Майкл насчитал 17 854 факторов ранжирования — при том, что некоторые файлы отсутствовали. Стоит отметить, что некоторые факторы повторяются. Кстати, в статье можно найти ссылку на готовый XLS-файл со всеми факторами в совокупности — правда для скачивания потребуется ввести корпоративный email-адрес.
Утечка данных помогла SEO-специалистам получить косвенные подтверждения гипотез, связанных с продвижением в «Яндексе». При этом до сих пор непонятно, насколько эта информация оказалась применена. Часто сеошники рассуждают так:

частный SEO-специалист
Обычно как происходит. Допустим, Google выкатил очередной апдейт. Потом известные SEO-шники с достаточными ресурсами, проводят различные тестирования и выдают информацию в массы. После слива ждал подобного, но шум утих и никто ничего пока так и не написал. На это как по мне есть 2 причины:
- Прошло слишком мало времени для внедрения и получения результатов.
- Возможно, ничего революционного в этом сливе просто нет.
Из-за этого важные данные распространяются в профессиональной среде медленнее, чем могли бы. Многие ждут сигнала от своих авторитетов, прежде чем начать разбираться в чем-то самому.
Почему утечка этой информации не является рецептом для попадания в топ «Яндекса»:
- в архиве присутствовали не все файлы, связанные поисковым алгоритмом,
- значительная часть факторов ранжирования будет понятна только сотрудникам «Яндекса» – у некоторых из факторов нет описаний, также у читателей не будет доступа к вики «Яндекса»,
- поисковый алгоритм «Яндекса» постоянно самосовершенствуется и регулярно обновляется – часть данных могла утратить актуальность.
При этом, утечка данных будет мощным подспорьем для SEO-специалистов в выстраивании новых гипотез и их проверке. Ключевые требования к оптимизации сайтов для «Яндекса» известны публично — этих знаний хватит с головой для первичной оптимизации. Информация из архива и этой статьи пригодится SEO-специалистам, чтобы точечно дооптимизировать свои проекты.
Если же вы не SEO-специалист, а интересующийся маркетингом бизнесмен, лучше почитайте нашу статью: «Как продвигаться в Google». Там информация более устоявшаяся и обкатанная. Эта статья будет более полезна SEO-специалистам, которые хотят получить баллы за или против каких-то своих гипотез.
Мы изучили опубликованные материалы касаемо утечки и подготовили саммари. Также спросили у опытных SEO-оптимизаторов, что они думают о «сливе» спустя некоторое время: сильно ли он повлиял на их подход при оптимизации? Поехали.
Как устроен алгоритм поисковой выдачи «Яндекс»
Для того, чтобы оценить влияние факторов ранжирования на поисковую выдачу, нужно понимать, как в целом устроен алгоритм. Вкратце перескажем пресс-релиз «Яндекс».
Поисковую выдачу регулирует Матрикснет. Это метод машинного обучения, который заменяет формулу с огромным количеством переменных, где каждая будет итоговой оценкой определенного фактора ранжирования. По сути, Матрикснет оценивает результаты ранжирования каждого отдельного фактора, которые реагируют самостоятельно на пользовательский запрос. Отдельные оценки факторов кэшируются, чтобы серверы «Яндекса» быстрее давали пользователю необходимый ответ. Архитектура с Матрикснет во главе позволяет за доли секунды обрабатывать миллионы страниц с контентом в рамках сложного алгоритма.
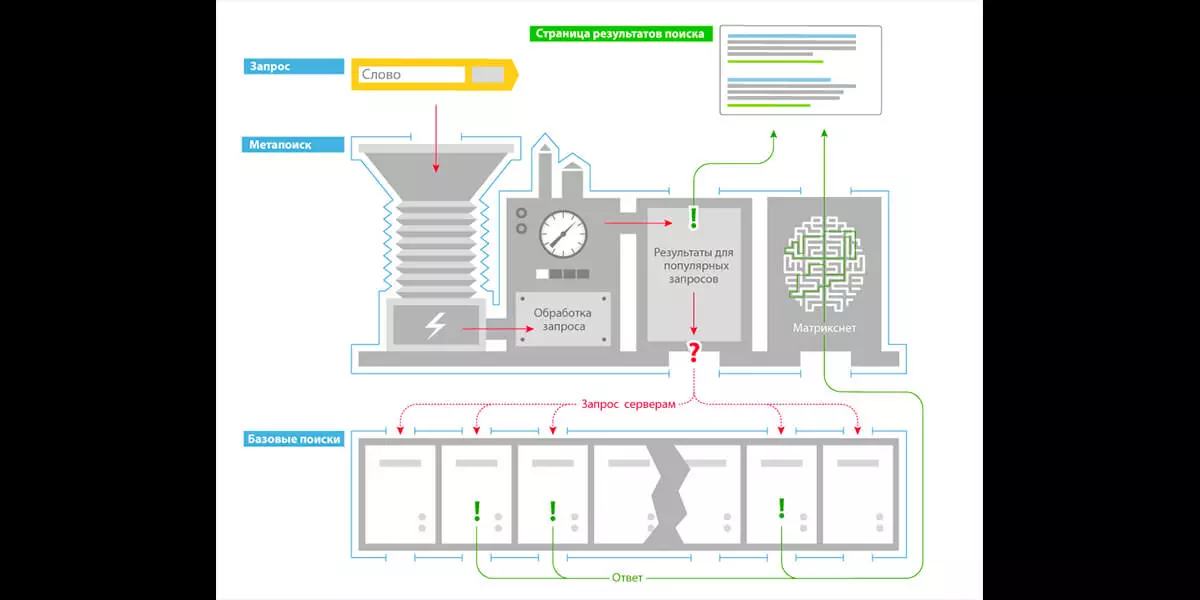
«Яндекс» пишет, что Матрикснет учитывает десятки тысяч запросов — следовательно, в утечку попали далеко не все факторы.
Что еще можно сказать о Матрикснет:
- Матрикснет постоянно самообучается – итоговая формула со временем меняется,
- в зависимости от класса запроса, Матрикснет может учитывать только ряд факторов,
- степень влияния того или иного фактора ранжирования также может меняться.
Выходит, утечка все равно не дает полного представления об алгоритме ранжирования «Яндекса». В ней нет большей части факторов, а алгоритм все еще остается гибким и непредсказуемым. Тем не менее, на основе доступных данных можно построить некоторые выводы.
Как устроены факторы ранжирования «Яндекса»
Факторы ранжирования находились в текстовых форматах входных данных с расширением .in. Около 2 000 факторов находились в файлах для интерактивного блокнота Jupyter Notebook. Вероятно, что файлы для программы Jupyter Notebook содержали тестируемые факторы ранжирования, которые на тот момент не входили в основной алгоритм.
Все факторы ранжирования подчиняются определенной структуре, которая позволяет частично их классифицировать, а также понять, за что они отвечают.

Все факторы примерно схожи по структуре, но если какое-то свойство не установлено, строчки с этим свойством у фактора не будет. Например, у некоторых факторов нет свойства «Wiki», в котором содержится ссылка на внутренний глоссарий «Яндекса».
Что означают свойства факторов:
- Index – числовое обозначение фактора в документе,
- CppName – группа, к которой относится данный фактор,
- Name – название фактора,
- Ticket – скорее всего, идентификатор заявки на создание этого фактора,
- Tags – теги, которые классифицируют фактор,
- Wiki – ссылка на внутренние гайды «Яндекса»,
- AntiSeoUpperBound – если у этого свойства значение «1», SEO-оптимизаторы слишком заостряют внимание на этом факторе и его высокий показатель будет означать переоптимизацию,
- Description – описание, которое обозначает принцип работы фактора, иногда прямым текстом объясняет принцип работы фактора,
- DependsOn – принадлежность к той или иной группе факторов,
- Authors – разработчик или разработчики фактора ранжирования
- Responsibles – лица, которые ответственны за работу фактора,
- ImplementationTime – дата внедрения фактора в работу, если он актуальный.
По некоторым свойствам можно приблизительно определить, что это за фактор и как с ним работать. Много полезной информации о том или ином факторе дают его теги в поле «Tags».
Теги факторов ранжирования поискового алгоритма «Яндекса»
Разберем наиболее очевидные из тегов.
TG_DYNAMIC
Динамический фактор ранжирования — оценивает релевантность страницы поисковому запросу.
TG_STATIC
Статический фактор ранжирования — зависит исключительно от контента страницы.
TG_DOC
Полностью анализирует содержимое страницы.
TG_DEPRECATED
Неактуальный фактор, который не учитывается.
TG_DOC_TEXT
Фактор, который проверяет текст на странице.
TG_UNUSED
Неиспользуемый в данный момент фактор.
TG_UNIMPLEMENTED
Нереализованный фактор.
TG_NEURAL
Фактор, который работает на основе нейросети.
TG_BROWSER
Фактор, который учитывает пользовательское поведение в «Яндекс.Браузере».
TG_LINK_TEXT
Фактор, который учитывает анкор (текст) ссылки.
TG_LINK_GRAPH
Фактор, который учитывает ссылочный граф — связи между группой сайтов (вершин) за счет ссылок (ребер).
TG_BINARY
Бинарный фактор со значениями «да» или «нет».
TG_OWNER
Фактор, который зависит от репутации вебмастера и анализирует ее по истории работы в интернете и таким данным, как Whois.
TG_THEME_CLASSIF
Фактор, который учитывает тему контента: например, музыка или новости.
TG_COMMERCIAL
Фактор, который определяет, насколько коммерческое содержание страницы или запроса.
TG_LOCALIZED_COUNTRY
Фактор, который учитывает страну запроса.
TG_LOCALIZED_REGION
Фактор, который учитывает регион запроса.
Коэффициент фактора
В архиве по адресу /search/relevance/ находился файл nav_linear.h, который с наибольшей вероятностью указывает на коэффициент влияния фактора ранжирования на поисковую выдачу. В файле находилось всего 257 факторов ранжирования. В списке есть факторы как с положительным, так и отрицательным коэффициентом.
Разберем по 10 факторов с наибольшим и наименьшим коэффициентом.
10 факторов ранжирования «Яндекс» с наибольшим коэффициентом
1. FI_URL_DOMAIN_FRACTION: 0,5 640 952 971
Фактор, который проверяет, содержит ли доменное имя трехбуквия из запроса. В описании приводят пример: «Челябинская лотерея — chelloto». Запрос переводится в транслит, после чего анализируется процент запроса, который покрывается трехбуквиями. В примере это «che», «hel», «lot», «oto».
2. FI_QUERY_DOWNER_CLICKS_COMBO: 0,3 690 780 393
Описание дословно: «фактор, хитрым образом скомбинированный из FRC и псевдо-CTR». FRC — это внутренняя метрика «Яндекса», значение которой неизвестно.
3. FI_MAX_WORD_HOST_CLICKS: 0,3 451 158 835
Кликабельность самого выраженного слова в запросе. Пример из описания: «Для всех запросов, в которых есть слово „Википедия“, кликают на страницы „Википедии“». Фактор, который поднимает страницы в выдаче, если в них присутствует название бренда.
4. FI_MAX_WORD_HOST_YABAR: 0,3 154 394 573
Наиболее характерное слово запроса, которое соответствует сайту по данным «Яндекс.Бара» — поисковой панели.
5. FI_IS_COM: 0,2 762 504 972
Доменные имена, которые находятся в зоне .com.
6. FI_OQ_BCLM_PLAIN: 0,2 549 154 957
Фактор BCLM, который рассчитывается по запросному индексу для сайтов.
7. FI_OWNER_CLICKS_PCTR: 0,2 310 004 818
Фактор, который оценивает кликабельность сайта независимо от запроса.
8. FI_MAX_WORD_HOST_RANK: 0,2 302 571 448
Фактор, который оценивает внутреннюю метрику Host Rank по максимально выраженному слову запроса. Обычно это название сайта.
9. FI_QUERY_DOWNER_CLICKS_PCTR: 0,2 195 950 362
Оценивает, насколько часто переходят на страницы по этому запросу. Оценивается так: CTR, который умножается на коэффициент.
10. FI_QUERY_DOWNER_CLICKS_FRC: 0,2 147 136 937
Отношение числа кликов по данному домену ко всем кликам по запросу.
10 факторов ранжирования «Яндекс» с наименьшим коэффициентом
1. FI_ADV: -0,2 509 284 637
Негативизация страниц с рекламой.
2. FI_DATER_AGE: -0,2 074 373 667
Проверяет разницу между текущей датой и датой страницы, которая определена датировщиком. Если дата равна текущей, значение будет «1». Если документу более 10 лет, значение будет «0». Судя по всему, значение умножается на коэффициент.
3. FI_QURL_STAT_POWER: -0,1 943 768 768
Количество показов URL-адреса по запросу. Рассчитывается по формуле: x/(100 + x).
4. FI_COMM_LINKS_SEO_HOSTS: -0,1 809 636 391
Доля входящих купленных ссылок, которая рассчитывается благодаря алгоритму распознавания коммерческих ссылок. Если таких ссылок более 50%, фактор приобретает значение «1», если меньше — «0».
5. FI_GEO_CITY_URL_REGION_COUNTRY: -0,168 645 758
Географическое совпадение URL-адреса страницы и страны, из которой осуществлялся запрос. Неизвестно, какой результат будет положительным, а какой — отрицательным.
6. FI_URL_PATH_AND_PARAMS_FRACTION: -0,1 622 206 168
Такой же фактор, что и предыдущий, но URL-адрес страницы учитывается без доменного имени.
7. FI_OWNER_SDIFF_CLICK_ENTROPY_REG: -0,160 285 062
В описании указано: «Энтропия — распределение кликов. Регионализованный.» Скорее всего, фактор рандомизирует региональную выдачу.
8. FI_PCT_LINKS: -0,1 416 682 025
Фактор, который реагирует на релевантность ссылки.
9. FI_CLASSIF_IS_SHOP: -0,1 339 319 854
Фактор, который отслеживает «магазинность» страницы. Ныне не используется (помечен тегом Deprecated).
10. FI_ESHOP_VALUE: -0,1 238 147 189
Актуальный фактор, который отслеживает «магазинность» страницы.
По этому списку видно, что с неполными данными трудно оценить, как влияют те или иные факторы на поисковую выдачу. Некоторые из факторов невозможно расшифровать, потому что у них нет описания или оно написано на внутреннем сленге работников «Яндекса».
Мнения SEO-специалистов об утечке данных

частный SEO-специалист
Сам по себе слив я считаю довольно интересным. Он позволяет утвердиться во мнении относительно разных догадок, являются они факторами ранжирования или нет. И без слива было ясно: чем лучше поведенческие метрики — тем лучше для ранжирования.
Но, к примеру, я не был уверен, является ли кол-во ссылок с 4хх кодом ответа фактором ранжирования. Я заменял их на рабочие, чтобы пользователи попадали на нужные страницы сайта, а также чтобы не тратить на них краулинговый бюджет поисковых ботов. Как оказалось, они также учитываются в «Яндексе» как отдельный фактор ранжирования.
Но в данном сливе отсутствуют данные о значимости того или иного фактора, и это не позволяет нам выстраивать приоритетность в работе над ними.
Поэтому данный слив считаю безусловно полезным, но больше как некий справочник для подтверждения гипотез: является ли тот или иной фактор ранжирования таковым, или нет.

частный SEO-специалист
Думаю, что для многих SEO-специалистов большинство факторов были известны и до слива данных. Тем не менее, такая информация помогает подтвердить или опровергнуть некоторые гипотезы. Лично я смотрел и сам файл слива, и некоторые разборы (файл достаточно большой и без расшифровки немного трудно в нём ориентироваться). Вот, что могу для себя выделить:
1) Что удивило?
В файле было много информации касаемо ссылок (как внешних, так и внутренних). Возраст ссылок, баланс ссылочной массы, анкоры ссылок и так далее. Яндекс заявлял о значительном уменьшении их влияния (и это заметно на практике), но в документе много информации на этот счёт. Судя по всему, раньше было ещё больше, теперь этот фактор значительно уменьшился, но всё равно ещё остаётся.
Еще неожиданно, что домен .com более приоритетный, чем .ru. Или, что цифры в URL могут влиять негативно.
2) Что ещё ожидал увидеть?
Мало информации касаемо текстовых факторов ранжирования: тексты должны быть хорошими, не дублироваться, мета теги без переспама и на этом всё.
Также нет информации, как отзывы влияют на ранжирование. Раньше была гипотеза, что много плохих отзывов о компании (например, в картах Яндекса), негативно влияют на ранжирование, но в файле про это информации нет.
3) Что подтвердилось?
Всё ещё необходимо следить за техническим состоянием сайта: битые ссылки, дубли страниц и прочее негативно сказывается на ранжировании. Некоторые специалисты мало уделяют этому внимание.
Платный трафик и трафик из других источников положительно влияет на ранжирование (не SEO единым, так сказать). Ранее слышал мнение, что он помогает только в расчете поведенческих факторов для молодых сайтов. Но сейчас очевидно, что это не так.
Плохие тексты могут негативно влиять как на саму страницу, так и на сайт целиком (хостовый фактор). Также поддерживал это мнение, и оно подтвердилось (хотя не все его разделяли).
Выводы: хотя большинство факторов было известно и ранее, подобные инфоповоды помогают взглянуть на них свежим взглядом, развеять некоторые мифы или подтвердить гипотезы. Развивайте свой сайт, следите за конкурентами и делайте чуть лучше, чем у них, давайте лучший ответ на запрос пользователя и долгожданный SEO-трафик не заставит себя долго ждать. Ну и про ссылки не забывайте!
Краткий чек-лист самых важных выводов из утечки
В этом списке мы собрали рекомендации, которые относятся к факторам с самыми значительными положительными и отрицательными коэффициентами. Следовательно, они сильнее всего влияют на позиции сайта в поисковой выдаче «Яндекса».
Наиболее важные выводы:
- Реклама на сайте негативно влияет на поисковую выдачу – старайтесь использовать ее реже и эффективнее.
- При возможности, обновляйте контент на старых страницах вместо того, чтобы создавать новые.
- Убедитесь, что большинство ваших ссылок имеют анкорный текст с упоминанием бренда.
- Старайтесь включить наиболее частотный целевой запрос в доменное имя, пускай даже без точного вхождения ключа.
- Домены .com ранжируются лучше, чем .ru.
- Стимулируйте пользователей чаще использовать брендированные поисковые запросы – за этим следят «Яндекс.Браузер» и «Яндекс.Бар».
- Работайте над увеличением CTR страниц вашего сайта в поисковой выдаче – CTR влияет на ранжирование.
на журнал







