

Автор статьи
Обновление статьи от 26.12.2024
В самом начале статьи давайте вспомним, что это такое — семантическое ядро.
Простыми словами, семантическое ядро сайта — это все запросы, которые ищет целевая аудитория сайта в поисковиках. Например, если сайт — интернет-магазин по продаже мебели, поисковые запросы его целевой аудитории будут такими, как «купить кровать», «купить мебель в гостиную», «бежевый диван» и так далее. Составление семантического ядра в SEO одна из ключевых задач, которую нужно выполнить корректно, чтобы остальные работы принесли наибольшую эффективность.
Сбор семантического ядра — непростая задача. Иногда оно может состоять из десятков тысяч запросов, но не переживайте — мы расскажем, как собрать семантику для сайта лучше ваших конкурентов.
Далее в статье:
- зачем нужно семантическое ядро,
- как создать структуру будущего сайта под внедрение семантического ядра,
- как собрать абсолютно все запросы,
- как сгруппировать (кластеризовать) запросы и подготовить их к внедрению на сайт.
Зачем нужно собрать семантическое ядро, если можно просто сделать сайт
- Чтобы получить максимум целевого трафика из поисковых систем (ваш кэп).
Если ваш сайт отработает все запросы целевой аудитории — он будет конкурировать за весь органический трафик. Конечно, он не займет первые места по всем запросам в выдаче — это зависит от десятков других факторов ранжирования. Но вы хотя бы начнете за них бороться и будете получать какую-то долю от всех переходов ваших потенциальных клиентов. А в этом и заключается главная цель SEO.
- Чтобы сделать сайт удобным для пользователей.
Допустим, вы торгуете бензогенераторами и вашему интернет-магазину соответствует запрос «купить бензогенератор 5 кВт». Если создать под этот поисковый запрос отдельную страницу, на которой будут продаваться только пятикиловатные генераторы, вашим клиентам будет проще найти нужный товар.
Или еще пример: представим, что вы занимаетесь разработкой сайта для компании, которая строит частные дома. Вы находите поисковый запрос «проект дома 3d». Становится ясно, что на страницах проектов должны быть их 3D-модели. Пользователям это нужно — некоторые из них хотят рассмотреть проект дома получше, покрутив его модельку и оценив ее с разных сторон.
Именно поэтому поисковые системы стремятся выше показывать сайты с качественной проработкой семантического ядра. Чем лучше будут сайты в верху выдачи, тем полезнее будет сам поисковик, отчего им будут чаще пользоваться. Если поисковиком больше пользуются, он приносит больше прибыли своей IT-корпорации — тут все очевидно.
- Чтобы не «запороться» на других факторах ранжирования поисковыми системами.
Например, от структуры семантического ядра будет зависеть структура самого сайта, а от нее — распределение ссылочного веса между его страницами. Прошло лет 15, а PageRank страниц до сих пор остается одним из важных факторов ранжирования сайта в поисковиках, а его оптимизация — важной частью работ в SEO. Но не буду заострять на этом внимание, потому что статья о другом.
Вообще, делать сайт без оглядки на SEO – рисковая затея. Об этом мы рассказали в статье: «Как и зачем учитывать требования поисковой оптимизации до разработки сайта». Там не только про то, как собирать семантику сайта и внедрять ее, но и про особенности технической оптимизации – рекомендую к прочтению.
А теперь к основной части.
Как собирать поисковые запросы для семантического ядра
Начну с базовой теории — рекомендую ее к прочтению тем, кто ранее не занимался подбором поисковых запросов и плохо представляет, что это такое. Если вам это знакомо — переходите сразу на первый этап.
0 этап. Изучение теории
У поисковых запросов есть частотность — прогнозируемое количество запросов фразы в поисковике в месяц. Семантическое ядро собирают только из фраз, у которых есть эта самая частотность — зачем внедрять на сайт фразы, которые никто не ищет?
Лучшим и единственным инструментом для подбора поисковых запросов в рунете был и остается Яндекс.Вордстат. Сервисы Google не давали таких возможностей для сбора семантики даже до ухода Google Ads из России. В Вордстате можно увидеть, насколько часто люди ищут в Яндексе тот или иной поисковый запрос. Эти данные более-менее справедливы и для оптимизации сайта под Google — вряд ли пользователи другого поисковика иначе выражают свои запросы.
Дисклеймер. Прежде чем взяться за сбор семантического ядра, вы должны знать базовые принципы работы с поисковыми запросами в SEO — иначе от ошибок ваша работа будет неэффективной. Но мы подготовились — у нас есть гайды, которые вам помогут.
Что нужно, чтобы правильно собрать и внедрить семантическое ядро:
- Уметь определять интенты поисковых запросов.
Интенты — это пользовательские намерения — то, что пользователь ожидает увидеть при вводе того или иного ключевого запроса. Если не уметь определять интенты, вы наполните семантическое ядро нецелевыми запросами. Или просто неверно сгруппируете их и внедрите на неподходящие страницы.
Например, вы можете внедрить запрос «как разморозить холодильник» на страницу с холодильником, на которой его можно купить. Толку от такого внедрения нет — ваша страница проиграет в конкуренции страницам со статьями на тему «как разморозить холодильник». Дело в том, что когда люди вводят этот ключевой запрос, им неинтересен ваш товар, они хотят получить ответ на свой вопрос. В этом случае полноценная статья будет лучше удовлетворять намерение пользователя, чем небольшая приписка на странице с товаром.
Чтобы узнать больше, читайте гайд: Что такое интент поискового запроса в SEO
2. Уметь работать с Яндекс. Вордстатом
Иногда нужно применять операторы поисковых запросов, еще может понадобиться узнать региональную частотность и сезонность того или иного запроса. Также собирать семантику с «голым» Вордстатом неудобно — для этих целей используют расширения, такие как Wordstater. Без расширения каждый запрос пришлось бы копировать и переносить таблицу по отдельности, а с ним нужные ключи можно легко и удобно скопировать.
При этом, если собирать семантическое ядро на тысячи запросов, это неэффективно делать в Вордстате. Чтобы автоматизировать процесс подбора, используют специальные сервисы для сбора семантического ядра, такие как Key Collector, о которых я еще расскажу. Но знание Вордстата необходимо, чтобы эффективно работать с целым набором таких программ: оттуда они и берут свои данные.
Чтобы узнать больше, читайте гайд: Яндекс.Вордстат: как собрать всю статистику по поисковым запросам
Если прочли гайды или итак все знаете — переходим к практической части.
1 этап. Подготовка структуры страниц сайта для семантического ядра
Поисковые запросы, которые будут присутствовать в семантическом ядре, зависят от товаров и услуг вашего будущего сайта. Например, если вы торгуете бытовой техникой, в вашем каталоге наверное будут разделы с холодильниками, телевизорами, смартфонами и так далее. К этим разделам будут относиться подразделы — более узконаправленные страницы. Например, к разделу со смартфонами будут относиться отдельные модели смартфонов и смартфоны с определенными свойствами.
Для того, чтобы понять, какие поисковые запросы вас интересуют, вам нужно взять ваш каталог из товаров и услуг и составить на его основе схему. Нужно просто выписать те разделы и подразделы, что известны вам без погружения в поисковые запросы. Например, в случае с товарами это может быть вид товара и бренд.
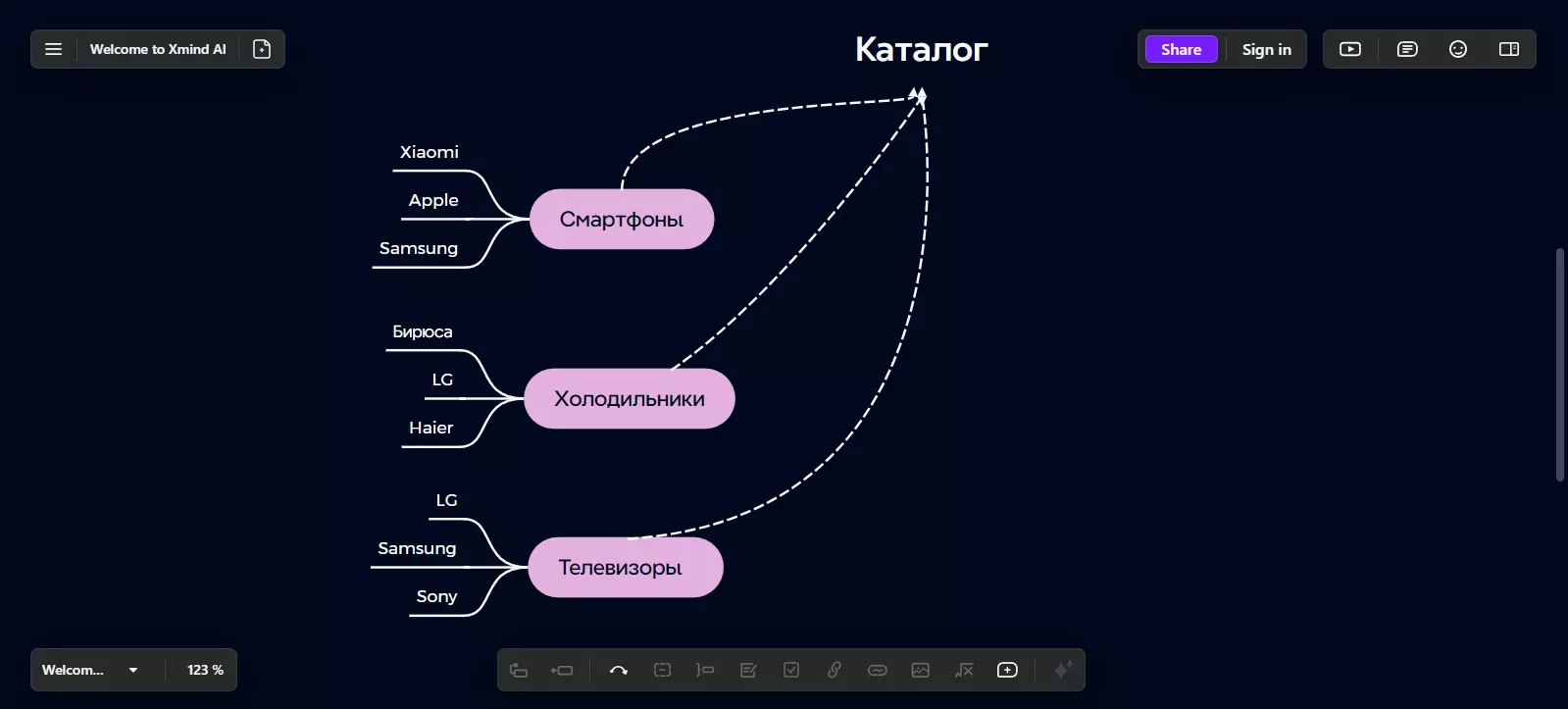
Составив такую схему, вы поймете, какие поисковые запросы вам нужно искать для продвижения в поисковиках и ничего не упустите при подборе, поскольку будете периодически возвращаться к схеме.
Позже, по мере работы с ключевыми запросами, эту схему нужно будет развивать, потому что у отдельных разделов появятся другие общие свойства. Например, при вводе запроса «смартфон» вам попадутся такие запросы, как «белый смартфон», «синий смартфон», «черный смартфон». Вы сможете объединить эти запросы по общему свойству — цвету, чтобы добавить его и его вариации в майнд-карту.
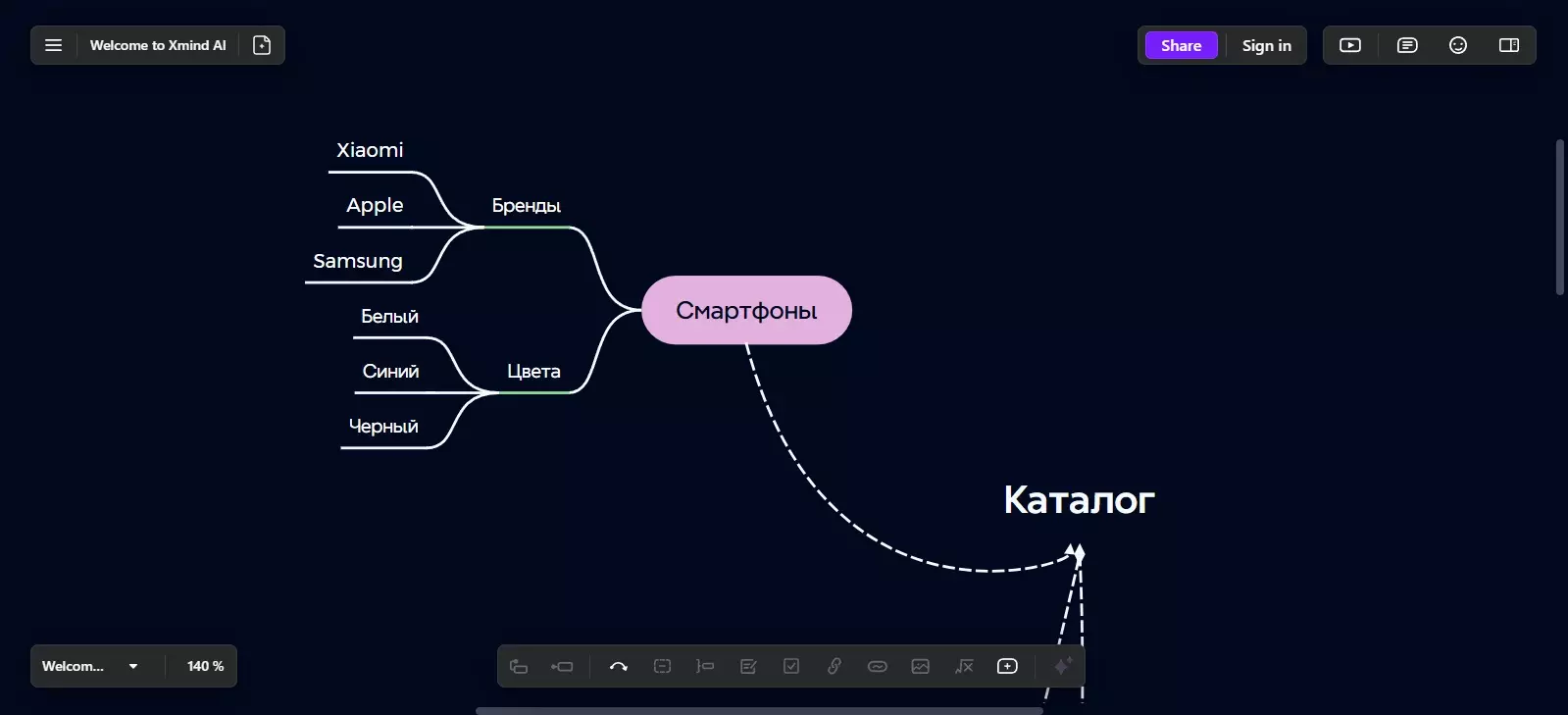
Схему нужно развивать, чтобы в будущем находить перекрестные расширения поисковых запросов. Например, вы сможете перебрать все сочетания ключевых запросов типа «раздел + бренд + цвет». Ими будут такие запросы, как «смартфон Samsung белый» или «смартфон Xiaomi черный». Если бренд продает исключительно смартфоны, запрос может быть и типа «бренд/модель + цвет», например «Poco белый». Поэтому важно составлять схему, чтобы продумать все возможные комбинации запросов и учесть их в своем семантическом ядре.
Но я уже немного забежал вперед — самое время переходить к работе с запросами.
2 этап. Сбор маркерных запросов
Для того, чтобы понять принцип работы с запросами, нам снова понадобится Яндекс.Вордстат. Ввожу туда запрос «смартфон» — вот что получилось.
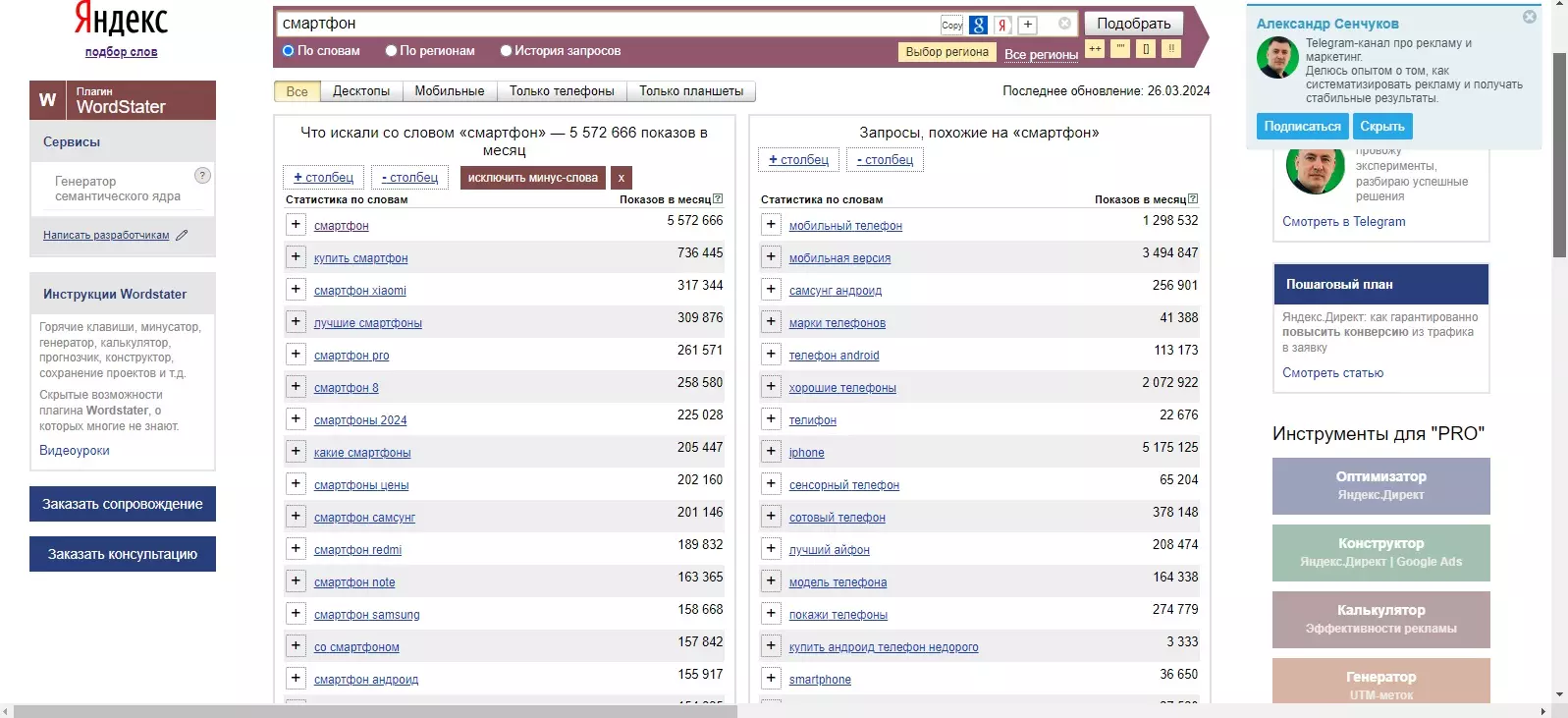
Сервис показывает, что слово «смартфон» люди ищут в Яндексе более 5 миллионов раз в месяц. Но важно то, что в эти 5 с лишним миллионов входят все возможные расширения поискового запроса «смартфон»: например, «купить смартфон», «лучший смартфон» и так далее. То есть, если сложить частотность всех расширений запроса «смартфон», получатся те самые 5 с лишним миллионов запросов.
В данной ситуации слово смартфон является маркерным запросом — верхнеуровневым запросом, соответствующим какому-либо разделу и имеющему дополнительные расширения. Расширения маркерного запроса «смартфон», такие как «смартфон Xiaomi» тоже могут быть маркерными запросами, потому что у них будут свои расширения.
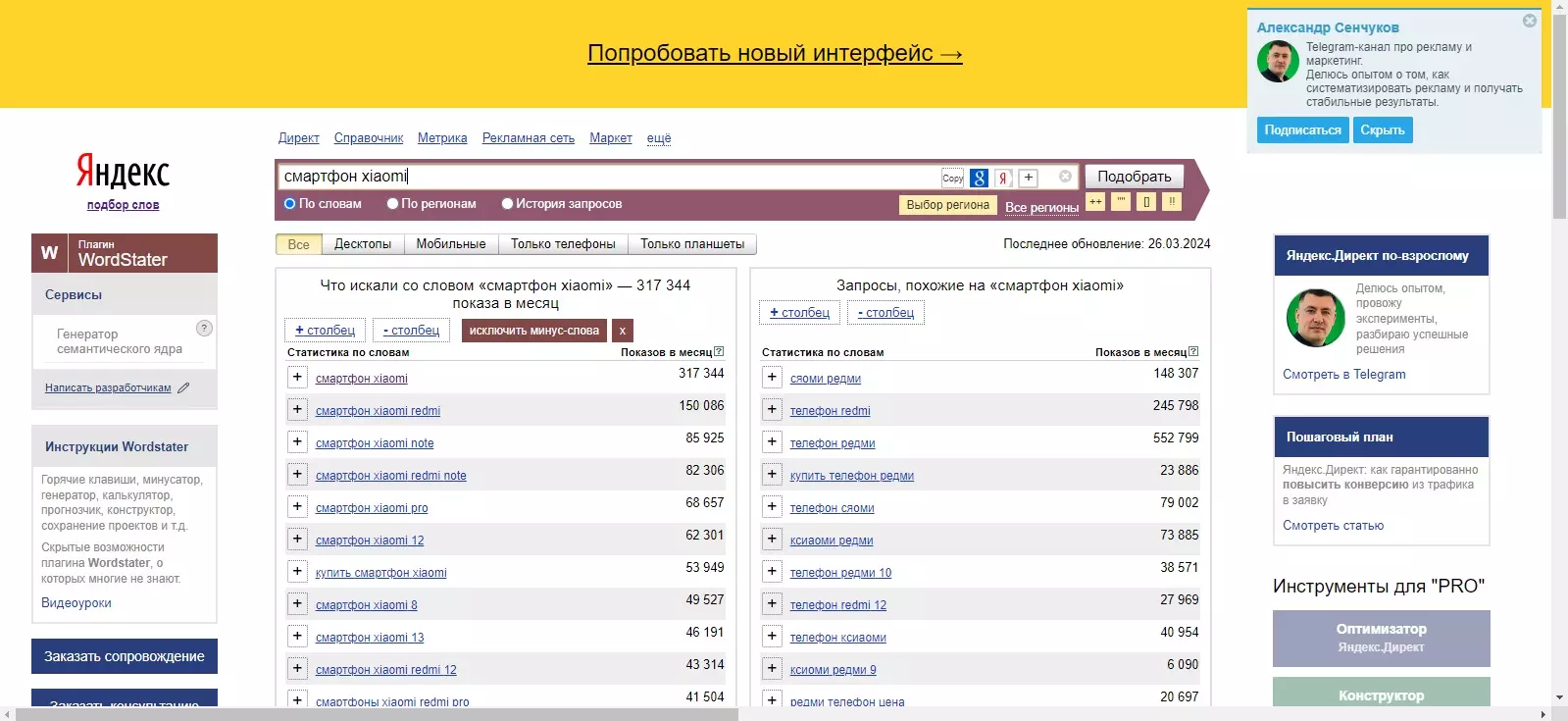
Далее вам нужно собрать все маркерные запросы, работая параллельно с майнд-картой. При сборе маркерных запросов важно учитывать все возможные вариации написания пользовательского интента, которые будут означать одно и то же.
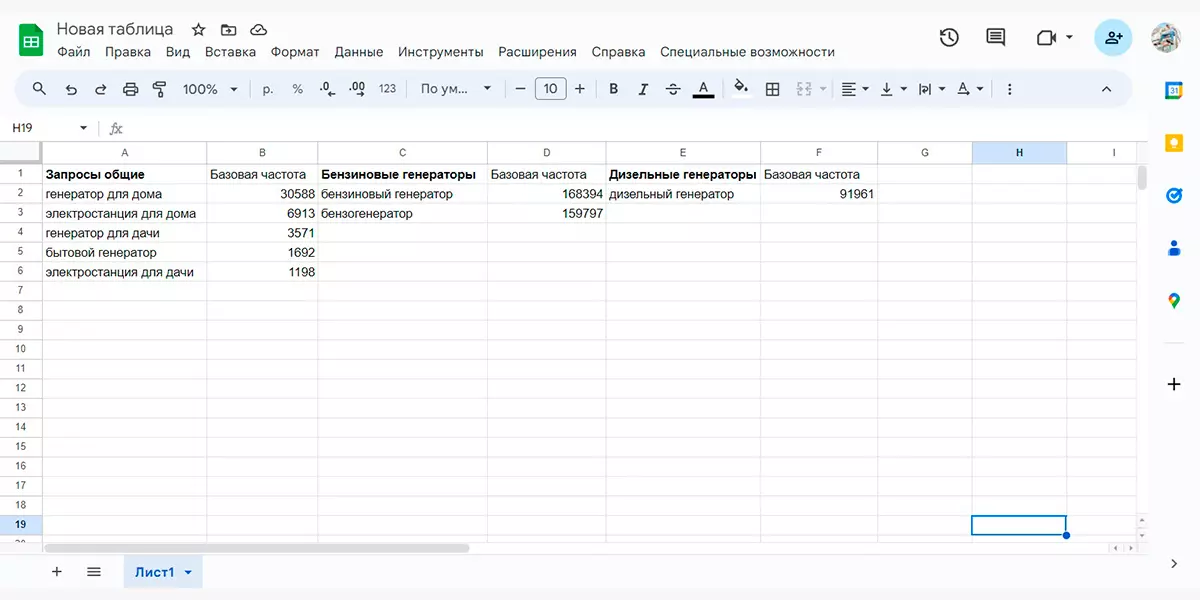
Например, запросы «бытовой генератор», «электростанция для дома», «электростанция для дачи», «генератор для дома» и «генератор для дачи» будут относиться к одному типу товара. Так же как и запросы «бензиновый генератор» и «бензогенератор» — но частотность этих запросов будет меньше, потому что просто генераторами интересуются чаще, чем бензиновыми.
Исходя из этого, вам нужно собрать основные группы запросов, по которым вы будете собирать «хвосты» семантического ядра — ключевые слова с расширениями.
Лайфхак. Можно сделать отдельные группы даже для запросов с одним и тем же пользовательским интентом, таким как «бензогенератор» и «бензиновый генератор». Так вы сможете создать отдельные посадочные страницы для продвижения под каждую из групп запросов. На этих страницах могут быть одинаковые товары, но если вы добавите на каждую из страниц немного уникального текста вдовесок к уникальным title, description и H1, поисковики будут думать, что это разные страницы. Если фокус не пройдет, страницы можно еще сильнее уникализировать, добавив в них дополнительных блоков с разным контентом.
После того, как вы соберете все маркерные запросы, можно перейти к следующему этапу — сбору их расширений.
3 этап. Сбор расширений маркерных запросов и чистка семантического ядра
Расширения можно собирать двумя способами: вручную и автоматически. Для первого способа понадобится Яндекс. Вордстат с расширением Wordstater для Google Chrome, а для второго — специализированные сервисы, такие как Key Collector.
Вручную
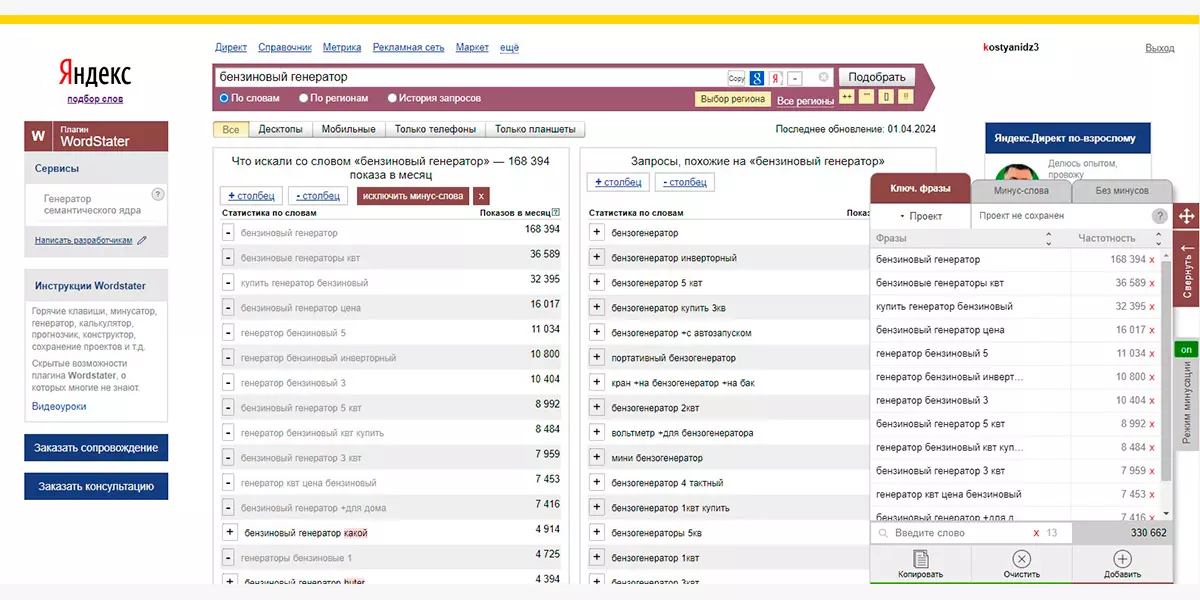
Если использовать набор из Вордстата с Wordstater, вы будете просто собирать вручную подходящие вам ключи, а неподходящие — пропускать. Расширение нужно, потому что с ним можно быстро копировать и выгружать запросы — без него каждый запрос приходилось бы копировать и вставлять в таблицу вручную. Еще у расширения есть «минус-режим», в котором вы можете кликать на неподходящие слова, занося их в минус-список, который вам может пригодиться: например, для настройки контекстной рекламы. Или для для автоматической фильтрации ключевых слов у групп со схожими запросами, родственных той, что вы собирали вручную.
Рассказывать, как именно работать с расширением не буду — на его установочной странице есть видеоинструкция.
Читайте также: Руководство по ведению блога. Личный опыт
Автоматически
В Key Collector можно создать отдельные группы для каждого маркерного запроса и запустить сбор данных из Яндекс.Вордстат. Для этого вам понадобится платная лицензия программы и активная почта Яндекса, которую вы должны добавить в сервис, потому что без нее не получится парсить (скачивать) данные Вордстата. Для этой функции сервиса тоже есть инструкция.
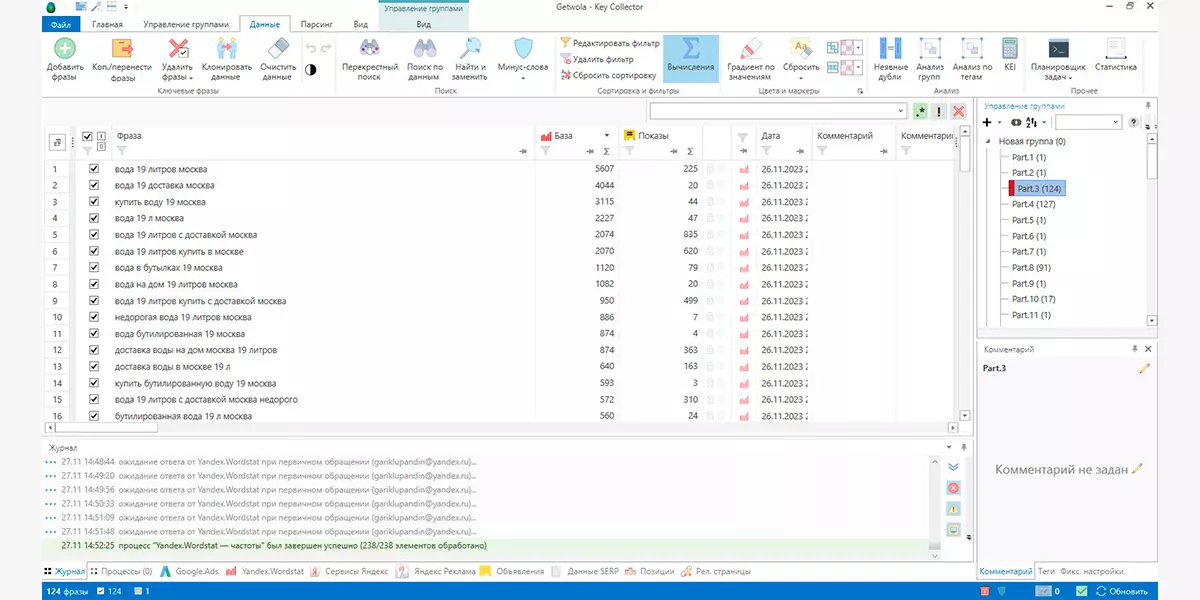
Собирать запросы с помощью сервиса гораздо быстрее, но есть сложность — он будет грести все подряд, в том числе и неподходящие запросы. Но Key Collector поддерживает чистку запросов с использованием списка минус-фраз.
Например, вы можете выгрузить все расширения запроса «бензиновый генератор» и собрать минус-фразы этой группы вручную. Затем вы можете выгрузить все расширения запроса «дизельный генератор» и отфильтровать ключи списком минус-фраз, которые вы собрали, работая с группой «дизельный генератор». Если вы будете собирать несколько групп аналогичного товара и копить минус-фразы, автоматический сбор каждой новой группы будет даваться все легче. Но когда вы перейдете к другим товарам, например смартфонам, там нужно будет составлять новый список минус-фраз и работать с ним.
Что ж, представим, что вы собрали все расширения нужных вам маркерных запросов и собрали их список в таблице.
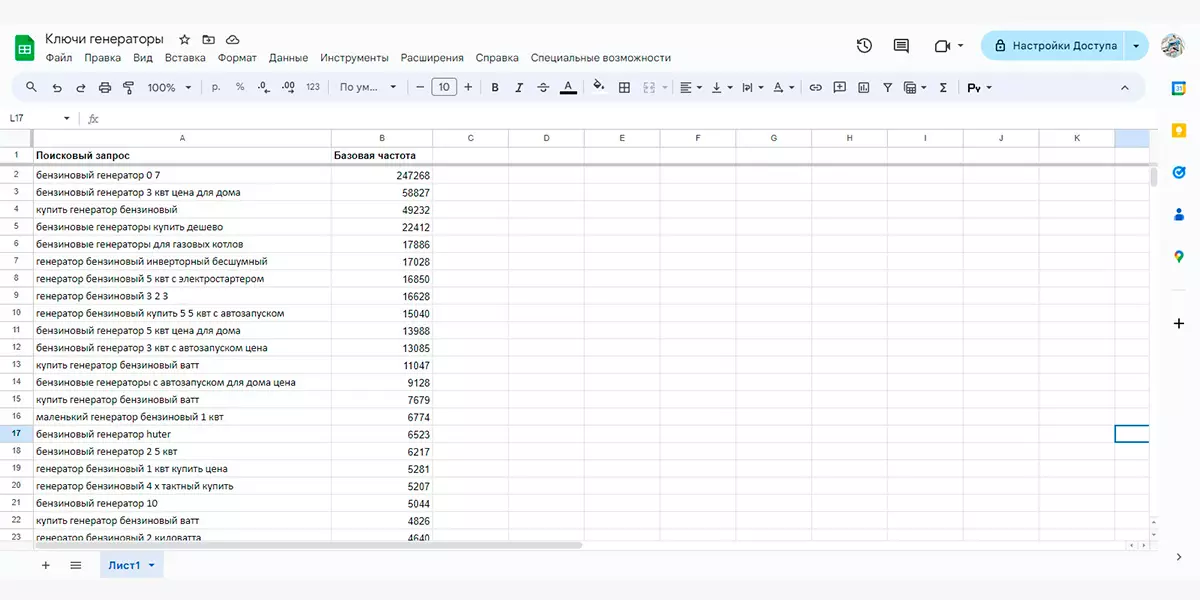
Видно, что в этом списке все смешалось в кучу: есть генераторы на 1, 3, 5 кВт и так далее. Чтобы эффективно внедрить все эти запросы на сайт, их нужно кластеризовать — распределить по однородным группам. Можно сказать, что каждый такой кластер — семантическое ядро страницы сайта в отдельности.
Далее расскажу, как заниматься кластеризацией.
4 этап. Кластеризация семантического ядра
Разумеется, кластеризовать запросы тоже можно и вручную, и автоматически. Рассмотрю оба способа.
Вручную
Ну тут все просто — берете и распределяете массив запросов по какому-либо свойству. Например, в случае с генераторами это могут быть киловатты: собираете запросы на генераторы с разными киловаттами в отдельные группы и все.
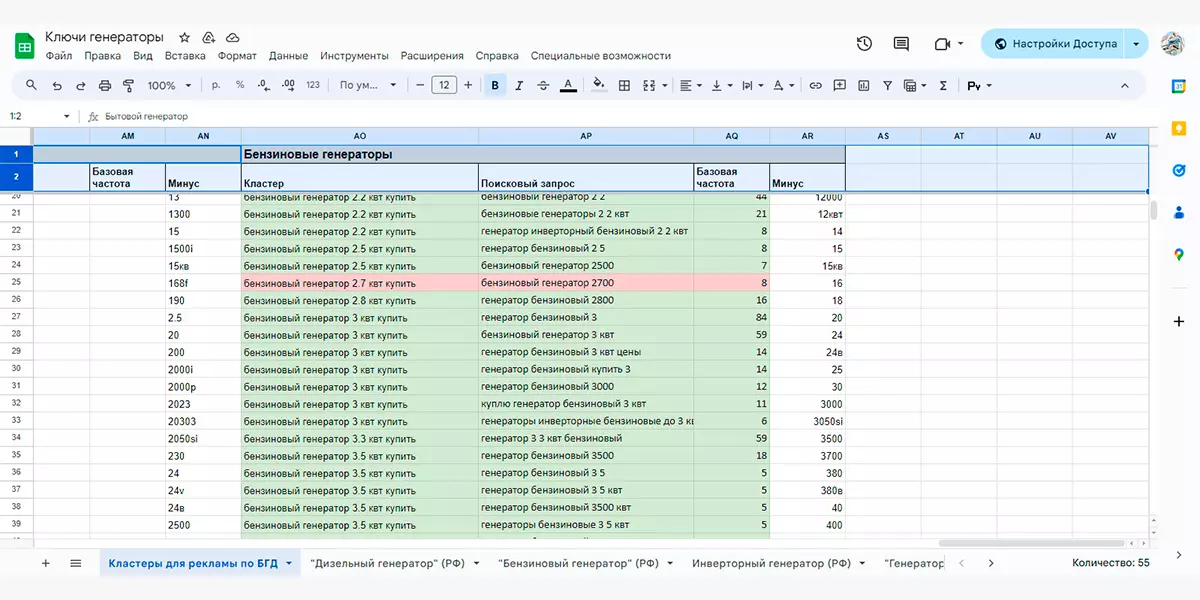
Иногда запросы нужно группировать по двум, а то и трем свойствам. Например, запрос с генератором может включать в себя не только мощность, но и бренд.
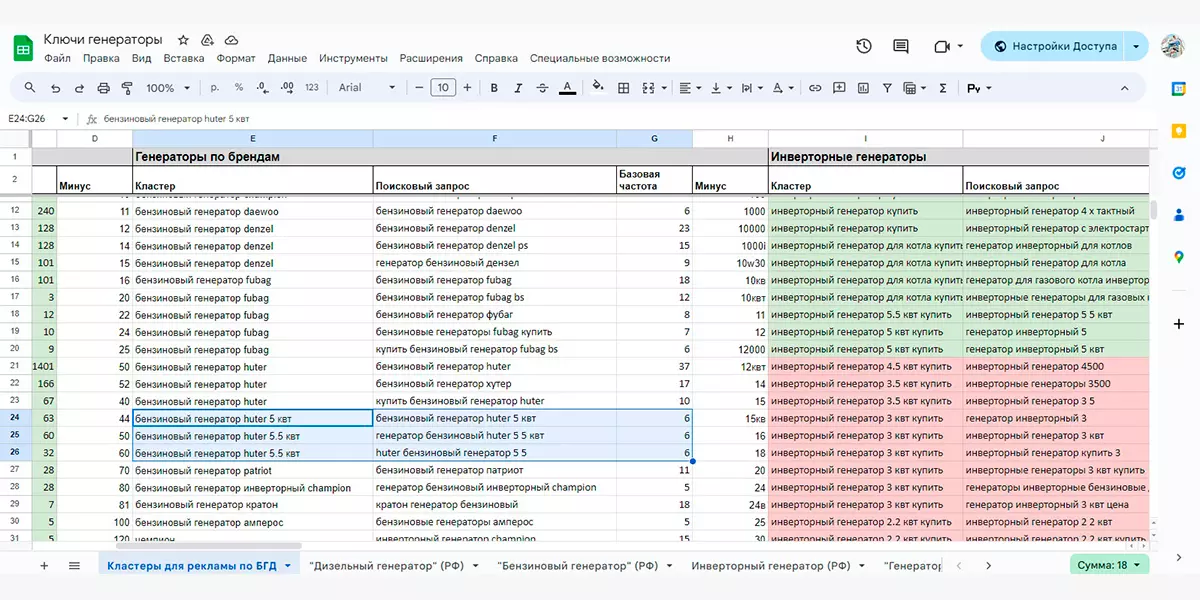
В общем, запросы можно сортировать вручную — этот процесс можно назвать анализом семантического ядра с его доработкой. Но если их тысячи, заниматься этим довольно проблематично. Тогда стоит использовать автоматическую кластеризацию.
Автоматически
Для автоматической кластеризации можно использовать как онлайн-сервисы, так и Key Collector — в последнем эта функция называется «Анализ групп». Онлайн-сервисов для кластеризации много: например, функцию поддерживают Пиксель Тулс, Rush Analytics, Арсенкин, Keys.so и так далее.
Существуют два основных способа автоматической кластеризации: по результатам выдачи и по сходствам в запросах.
При кластеризации по результатам выдачи сервис анализирует страницы, которые уже есть в поисковой выдаче и смотрит, какие запросы на них сгруппированы в один кластер. Есть разные режимы такой кластеризации, например soft и hard. Soft — это мягкая кластеризация, при которой запросы могут объединяться по одному свойству: например, генераторы одного бренда, но с разными киловаттами. При hard-кластеризации такие же запросы будут разделены на разные группы.
Еще в сервисах можно настроить степень кластеризации — это количество страниц выдачи, в которых поисковые запросы кластеризованны точно так же. Например, степень «3» означает, что поисковые слова должны быть так же сгруппированы как минимум в трех страницах из первых 10 страниц выдачи.
При кластеризации по сходствам в запросах сервисы находят в поисковых запросах схожие слова и по ним создают группы.
Важно: результаты автоматической кластеризации лучше проверять — иногда получается не очень. Чтобы добиться нужного результата, иногда нужно поэкспериментировать с настройками или доработать вручную.
А теперь подходим к завершающему этапу — внедрению поисковых запросов на сайт.
5 этап. Распределение запросов по сайту и посадочным страницам
Все запросы, которые вы кластеризовали, позволят вам собирать целевой трафик на ваш сайт. Чтобы максимально задействовать его поисковый потенциал, вам нужно создать посадочные страницы, которые будут максимально соответствовать интенту поискового запроса. Запросы внедряются в HTML-теги title, description, h1-h6 и текст сайта. Самые высокочастотные идут в title, description и заголовки H1-H6, а самые низкочастотные — в текст на сайте. Но не буду на этом фокусироваться, потому что статья о другом.
Так на какие страницы добавлять запросы? На те, что лучше всего удовлетворяют этот самый запрос или кластер запросов. Например, страница, у которой в title запрос «генератор купить» должна быть каталогом генераторов.
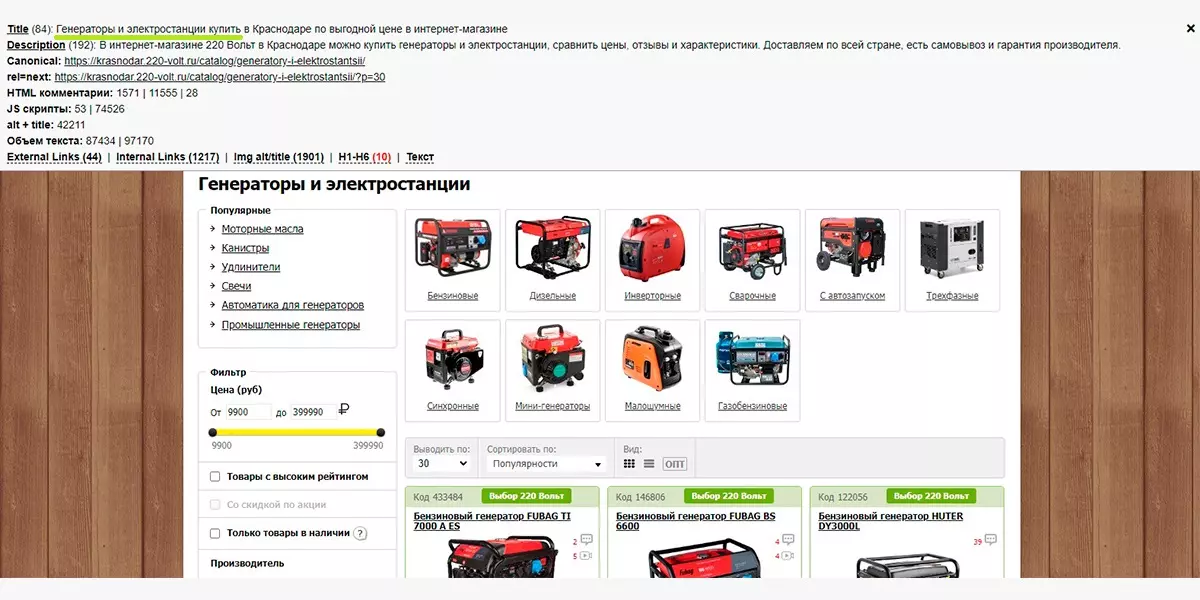
А страница с title, в который внедрен запрос «генератор huter 5 квт» должна содержать подходящие генераторы.
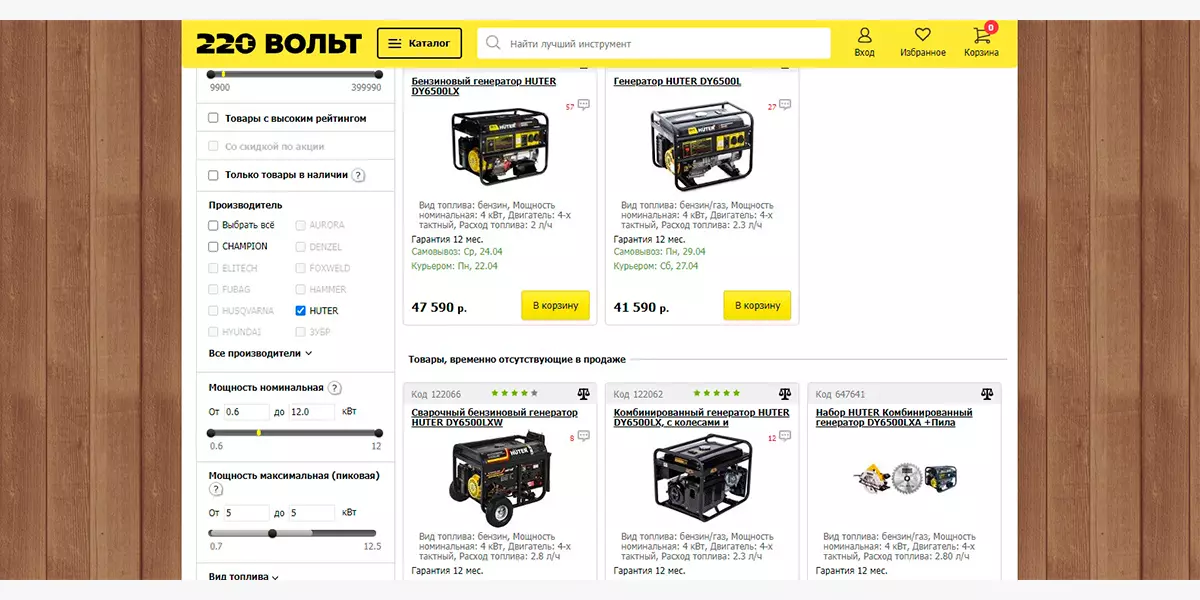
И вот таким способом, руководствуясь майнд-картой и таблицей с данными, вы должны нашпиговать свой сайт поисковыми запросами. Если вы создадите более релевантные (подходящие под запрос) страницы, чем у конкурентов, вы отберете у них весь трафик по низкочастотным запросам. Поэтому при создании сайта нужно учитывать семантическое ядро — оно повлияет на его будущую структуру и систему фильтрации контента: чаще всего, фильтрацию товара по свойствам.
Заключение
Есть и альтернативный способ сбора семантического ядра. С помощью тех же онлайн-сервисов можно скачать готовые семантические ядра конкурентов. Но среди их запросов будет много грязи: иногда чистить и кластеризовать такие запросы дольше, чем собирать самому. А еще конкуренты могут оказаться менее дотошными чем вы и упустить кучу релевантных запросов.
Так что не страдайте ерундой, и да: подписывайтесь на Telegram-канал Awake, чтобы не пропустить новые экспертные статьи про интернет-маркетинг и SEO в том числе :*
на журнал



