

Автор статьи, интернет-маркетолог
Показатели в Google Analytics и Яндекс. Метрике — не истина в последней инстанции. Это незаменимые сервисы, но их данные требуют корректировок из-за недоработок и багов. К искажениям в данных прибавляется их неверная интерпретация и умышленная манипуляция отчетностью. Все это становится причиной неверных управленческих решений, которые обходятся крупным компаниям в десятки миллионов рублей.
Объясним:
- как вышло, что сервисы веб-аналитики показывают данные, в большинстве случаев непригодные для отчетов,
- почему гипотезы, основанные на неверной интерпретации данных, бессмысленны,
- почему Google Analytics 4 хуже, чем Google Analytics 3,
- как работать с данными аналитических систем, чтобы отчеты отражали действительность.
Много примеров и фактуры взяли из выступлений Ильи Красинского — признанного эксперта в продакт-менеджменте, аналитике и юнит-экономике. Рекомендуем посмотреть записи его выступлений на YouTube, чтобы глубже понять специфику проблемы:
- «Илья Красинский - Как на самом деле работает Google Analytics»,
- «Илья Красинский, Rick.ai - О недооцененной конверсии и когортах»,
- «Илья Красинский, Rick ai - Как маркетологам и аналитикам считать эффективность кампаний».
Фундаментальная причина неточностей в веб-аналитике
Google Analytics заложила стандарты веб-аналитики. Это лидер рынка, ее по разным оценкам используют 60−80% всех сайтов мира. Важно подчеркнуть, что веб-аналитика — это отдельное направление, которое отличается от продуктовой, маркетинговой, сквозной аналитики и прочих направлений. Если рассмотреть особенности веб-аналитики с точки зрения технологий, это будут UTM-метки, а также механизмы определения сессии и канала привлечения пользователя.
На рынке присутствует много платных и бесплатных аналитических сервисов. Бесплатные — Google Analytics и Яндекс. Метрика, платные — OWOX, Roistat, Rick. ai и другие. Также существуют «звезды смерти» — самописные системы аналитики. На все эти продукты повлияла Google Analytics.
В качестве примера альтернативного развития технологий можно привести мобильную аналитику. Она изначально была user-based — считала пользователей и события. Например, такая архитектура у Amplitude и Google Analytics 4 — последней версии продукта, которая с 1 июля станет единственной рабочей версией. Классическая Google Analytics и все ее преемники пошли session-based путем. Они считали ключевые метрики по сессиям посещений сайта.
Ключевая проблема session-based-аналитики заключается в погрешностях при записи данных, если сравнивать их с реальностью. Особенно, если рассматривать данные в разрезе по пользователям и когортам. Пользователь провел более получаса на сайте — у него закончится старая сессия и начнется новая. Причин смены сессии достаточно много и они разные: например, переход по реферальной ссылке, смена суток, разница в часовых поясах в рекламном кабинете, аналитике и CRM. В итоге, такие данные приводят к неверным выводам.
Например, заходит человек на сайт и ему нужно привязать свою карту через какой-нибудь сервис, как Stripe. Когда пользователь перейдет по ссылке для привязки карты, будет создана новая сессия. Что в GA 3, что в GA 4 в качестве канала привлечения пользователя будет указан банковский сервис: stripe / referral. Это произойдет из-за разрыва сессий при переходе на сторонний сайт и атрибуции по последнему взаимодействию. Продажи будут идти на stripe / referral, хоть этот канал и не является каналом привлечения пользователя. В итоге, продажу недополучит рекламная кампания или посадочная страница.
Изначально Google Analytics была заточена под e-commerce на американском рынке. В ecommerce человек просто заходит на сайт и оплачивает товар карточкой — все в рамках одной сессии. В ту эпоху развития веба еще не было никаких наложенных платежей, транзакций в CRM, Web 3.0, SPA и прочего. Поэтому на первых порах такая архитектура веб-аналитики была приемлемой, но сейчас она морально устарела.
При этом, Google Analytics плохо подготовлена даже под ecommerce. В Google Analytics есть специальная метрика — eCommerceConvRate, которая интерпретируется многими как конверсия, но ей не является. ECommerceConvRate — это количество заказов, деленное на количество сессий. В свою очередь, конверсия — это количество пользователей с заказом, деленное на общее количество пользователей. Представьте, насколько сильно будут искажены данные, если воспринимать количество сессий как количество пользователей.
Google Analytics изначально не рассчитан под внедрение сквозной аналитики и имеет готовую интеграцию лишь с Google Ads. Для интеграции с другими сервисами Google предложили UTM-метки, но этот инструмент обладает своими проблемами. Например, UTM-метки могут слетать из-за редиректов или быть неверно записанными. Другой пример: в Facebook* Ads Manager есть баг, из-за которого неправильно записанная UTM-метка после исправления будет передаваться через Facebook* API в первоначальном виде.
В интеграции с Google Ads также есть баги и дефекты. Analytics и Ads — 2 разных механизма, которые работают по разным моделям атрибуции. Google Ads записывает GCLID — идентификатор клика, который приписывается заявке или заказу. Google Analytics фиксирует пользовательские сессии. Механизмы обеих систем были разработаны еще 15 лет назад и содержат набор противоречий, которые выливаются в проблемы атрибутирования событий.
В Google Analytics есть идентификатор User ID, который позволяет объединить пользовательские сессии, если пользователь заходил на сайт с разных устройств. Допустим, пользователь заходил на сайт со смартфона и с компьютера — у разных сессий будет разный Client ID, но общий User ID. При этом, он по умолчанию выключен и внедрять его сложнее, чем счетчик аналитики. К тому же, User ID делит пользовательскую воронку на две — до регистрации и после, поскольку User ID присваивается пользователю при вводе данных на сайте. Разбиение воронок не позволяет нормально анализировать сквозную конверсию.
И еще: у Google Analytics гигантская база данных. Данные дорого изменять и обсчитывать, а Google за это никто не платит. Те, кто работают с базами данных, знают, что запись информации — значительно более дешевый запрос, нежели поиск и изменение данных. Чтобы сэкономить, в Google Analytics 3 сэмплируют данные. Поэтому в ней нельзя назначать какие-то дополнительные события пользователям, например, при изменении статуса в CRM.
У session-based Google Analytics и ее преемников есть 3 основные проблемы архитектуры:
- UTM-метки, которые могут слетать от редиректов,
- session-based-аналитика, которая вызывает целый ряд проблем,
- невозможность пересчитать и изменить данные, потому что это очень дорого.
Яндекс.Метрика — продукт, вдохновленный ранней версией Google Analytics. Продукт Яндекса содержит уникальные функции, но во многом отстает от продукта Google. Главный недостаток Яндекс. Метрики — в ней нет проработанного механизма отслеживания событий. Для этого применяется JavaScript-метод reachGoal, но у него нет параметров и передачи данных по API. Из-за этого приходится отправлять виртуальные PageView. С ее помощью можно реализовать user-based-аналитику, но это делается через «костыли».
Читайте также: 10 самых важных метрик продукта
Почему неправильная работа с данными — то же самое, что бросок монетки
Из-за ряда проблем, в большей части отчетов Google Analytics и Яндекс. Метрика показывают некорректные данные. Неточности в данных настолько велики, что приводят к неверным управленческим решениям.
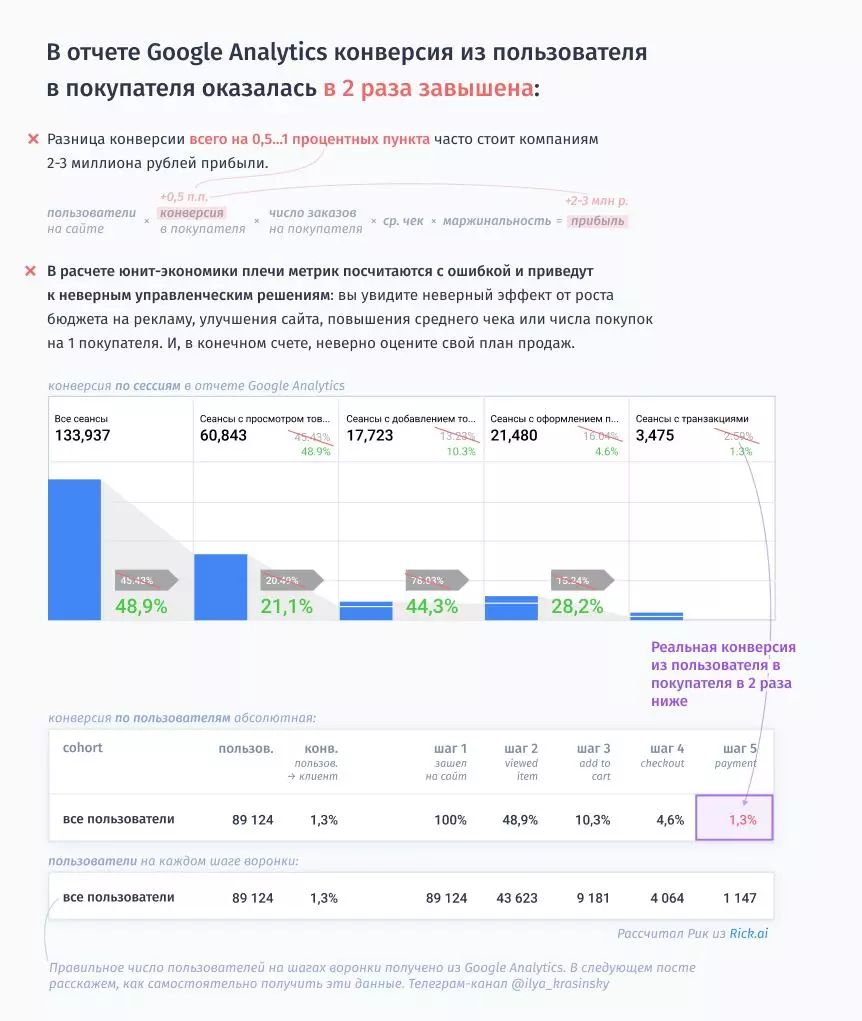
Например, если вы делаете A/B-тест или делаете новый лендинг, вы скорее всего не видите 20−40% конверсий. Они не видны из-за механизма атрибуции last-click, который пишет часть продаж не на посадочную страницу, а на промежуточные страницы, на которой у пользователей обновились сессии. На это умножаются сложности расчета данных по когортам новых и вернувшихся пользователей, которые не отображаются корректно ни в Google, ни в Яндексе. Также это множится на проблему того, что данные нужно смотреть в срезе по устройствам, разрешению экрана и прочему, чтобы в итоге оптимизировать конверсию. В системах аналитик много неточностей и багов, которые в совокупности настолько искажают данные, что делают A/B-тесты просто бессмысленными.
Когорты должны быть глубоко встроены в любой отчет. Например, когда человек смотрит отчет по каналам и кампаниям, нужно, чтобы не просто показывалось число пользователей в январе, а показывалось число транзакций в январе. Статусы заявок считаются когортами — важно знать, сколько из них было оплачено и за какой промежуток времени. Допустим, клиент оставит заявку 31 января, а оплатит в феврале. Если это не учитывать, в январском отчете клиент не будет не будет указан, хотя его привлекли с рекламы именно в январе. Без этого не получится подсчитать ROMI и оценить эффективность рекламных каналов для дальнейшей оптимизации.
Если в аналитическом сервисе показана конверсия в 3%, то это может быть и 9%, и 0,2%. Более того, она будет случайно меняться от канала к каналу и погрешности между каналами могут различаться в разы. Это все делает бессмысленным какие-либо выводы — проще кидать монетку.
Почему самописные системы аналитики — это «звезды смерти», которые не работают
Система сквозной аналитики — сложный механизм с большим количеством алгоритмов, который нужно тщательно тестировать, имитируя различные поведенческие ситуации. Даже если брать в расчет команды крупных IT-компаний, таких, как Яндекс и Mail.ru, ни одна из них не смогла с нуля создать систему сквозной аналитики. Все строили свои «звезды смерти», которые работали с неточностями.
Люди, которые пишут системы аналитики, сильно недооценивают сложность поведения системы. Нужно обладать большим количеством компетенций, чтобы создать систему без ошибок: от визуального представления информации до правильной модели хранения данных, которую можно сделать только итерационным путем. Очень немного специалистов работает над системами сквозной аналитики и обладают должной экспертизой.
Несмотря на проблемы Google Analytics, у нее есть около 40 алгоритмов, которые очень тяжело воссоздать с нуля. К ним относится алгоритм определения канала привлечения трафика. Живой пример: свою сквозную аналитику разрабатывает Roistat. Компания уже инвестировала в разработку своей системы аналитики около 250 миллионов рублей и продолжает инвестировать.
3 слоя искажений данных в отчетности
Итоговая отчетность, по которой принимаются управленческие решения, имеет 3 слоя искажений:
- Качество данных в системах веб-аналитики.
- Неправильная интерпретация данных.
- Умышленное представление аналитических данных под видом, что «все хорошо».
Первый слой — это недоработки и ошибки в аналитических системах. Системы аналитики на сессионной модели неправильно определяют канал привлечения, недозаписывают лидов нужному каналу или лендингу из-за last-click-атрибуции. Это приводит к тому, что почти всегда кампаниям недозаписываются продажи и они выглядят неэффективными. Стоимость лида/заявки/продажи обычно выше настоящей.
Сюда же относятся ошибки на стороне бизнеса. Например, в компании могли обновить сайт, из-за чего счетчик аналитики пропал с части страниц сайта.
Второй слой — это незнание людей, какие вопросы им задавать в данные. Если специалист не разбирается в юнит-экономике, продакт-менеджменте и устройстве систем веб-аналитики, он будет неверно интерпретировать данные. Большое количество специалистов считают, что искажения в веб-аналитике — это незначительная погрешность. В действительности ситуация такова, что искажения происходят постоянно.
Чтобы находить точки роста, нужно искать поведение пользователей, которое будет неожиданным для специалиста. Нужно не подтверждать свою точку зрения, а видеть, насколько людям сложно и неудобно использовать продукт, чтобы менять его в лучшую сторону. Люди, которые ошибаются, обычно «подтягивают» аналитические показатели к своим гипотезам, выдавая их за истину. Они придумывают свою воронку и считают, что пользователи себя так и ведут, а пользователи ведут себя гораздо сложнее.
Третий слой — это умышленная манипуляция показателями в отчетности, чтобы не вступить в конфликт с руководством или заказчиком.
Почему текущая версия Google Analytics 4 хуже, чем Google Analytics 3
Идеологически GA 4 сделан лучше — там есть событийная модель и пользователи. При этом, релиз Google Analytics 4 с точки зрения продакт-менеджмента был хуже, чем у Google Analytics 3 и Firebase. Например, у GA 4 уже полтора года есть баг, что UTM-метка из Google Ads не передается правильно с BigQuery в интерфейс Google Analytics 4. Канал записывается не как cpc, а как organic.
Чтобы оценить точность данных, предоставляемых системой Google Analytics 4, можно изучить официальную статью от Google: «Преодоление разрыва между пользовательским интерфейсом Google Analytics и экспортом BigQuery».
Текущая политика Google — обезличивание данных. Они ее ужесточили еще сильнее, хотя в Google Analytics итак нет никаких данных, которые нарушали бы конфиденциальность пользователя. Например, там уже давно не показываатся IP-адрес и прочее. Тем не менее, в GA 4 ввели такое понятие, как cardinality. Это означает, что строки отчета с небольшим показателем могут объединиться в «другие».
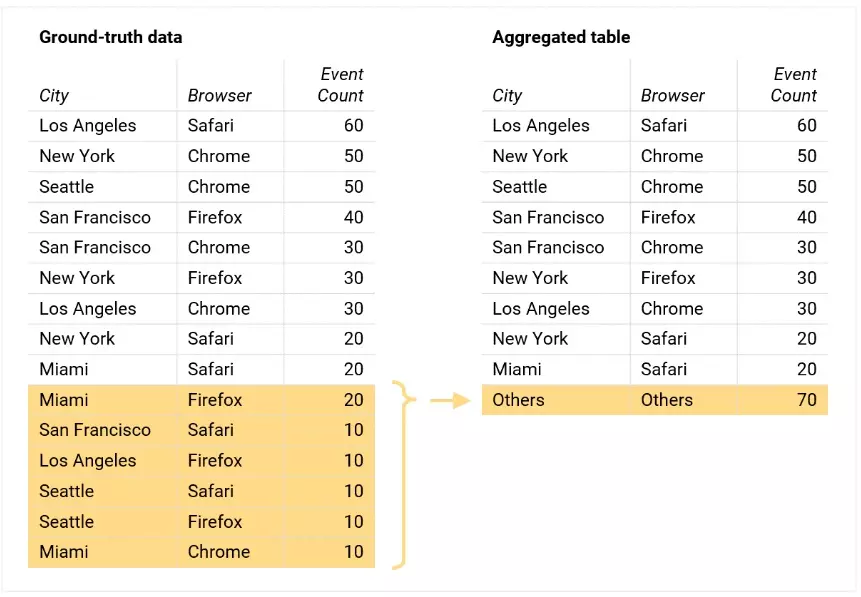
Например, если у вас много посетителей из каких-то городов, они будут представлены отдельно, а небольшое количество посетителей из других городов будут объединены в одну строку и их нельзя будет изучить детально.
Также в GA 4 ввели механизм Гиперлоглог++. Благодаря этому механизму, события в GA 4 показываются с определенной точностью. В статье пишется, что это ±1,63%, но это усредненный показатель. Он может быть изменен в любую сторону, самое паршивое, что погрешности будут отличаться между каналами. Например, в канале рекламы ВКонтакте погрешность может быть 1,1%, а в Яндекс. Директе — 2%. Она будет отличаться между собой у лендингов, устройств, когорт и прочих срезов.
В GA 4 ввели технологию Google Signals, которая уточняет данные, но ее обессмыслили за счет cardinality, Гиперлоглог++ и моделирования данных, о котором Google прямо заявили в разделе «Режим согласия и смоделированные данные». Google Signals уточняет данные примерно на 3−5%, но из-за него еще сильнее увеличиваются расхождения между данными в GA 4 и данными BigQuery — поэтому технологию лучше отключить.
Выходит, что эти данные еще менее точны, чем засэмплированные. Интерфейс GA 4 искажает данные и не позволяет создать кастомизированные отчеты из-за недоработок.
Как работать с данными систем веб-аналитики, чтобы они были точными
Общепринятый стандарт — использовать как минимум 2 системы аналитики. Если использовать только одну систему, данные в ней будут заведомо ложные.
Лучше всего брать сырые данные из BigQuery или ClickHouse и считать по ним метрики самостоятельно. Либо воспользоваться сервисом, который берет данные BigQuery, считает сам и по API выдает вам корректные данные. Лучше, если вы не берете данные из BigQuery напрямую, а применяете сервис, который умеет эти данные обрабатывать, правильно передавать, исправляет искажения и обогащает данные из других источников на своей стороне.
Читайте также: Как измерить эффективность контент-маркетинга для блога
*Соцсеть признана экстремистской и запрещена в России.
на журнал



